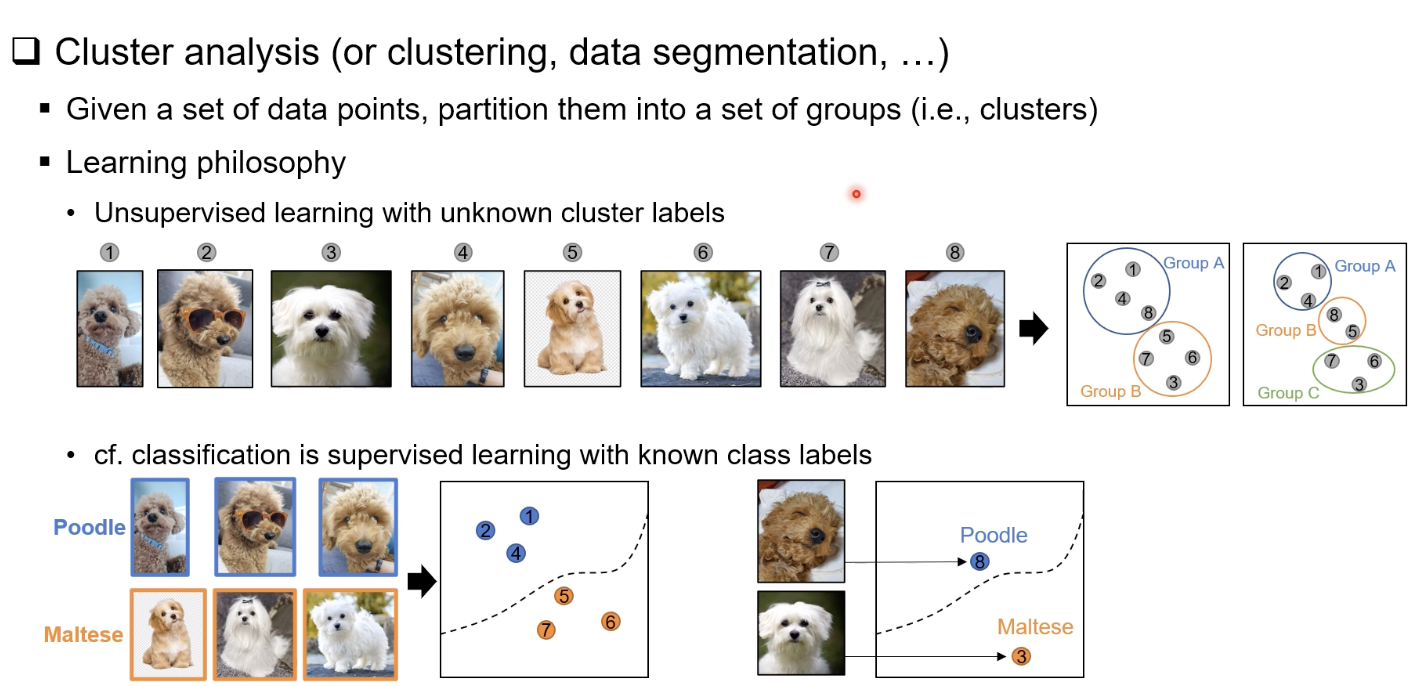
클러스터링이란 무엇인가
클러스터링은 라벨이 제공되지 않은 데이터에서 유사한 패턴을 가진 데이터들을 자동으로 묶어내는 비지도 학습 기법이다.
이 과정의 핵심은 “데이터가 어떤 기준으로 서로 비슷한가?”에 대한 정의이며, 이 기준은 알고리즘마다 다르다(거리, 밀도, 확률 등).
산업에서의 실제 의미
- 추천 시스템에서 고객 세그멘테이션
- 이상 탐지에서 정상 군집과 비정상 군집 분리
- 마케팅 타깃 그룹 정의
- 문서/FAQ 자동 군집화 (RAG 전처리 단계)
- 이미지 임베딩 기반 시각적 유사도 그룹화
즉, “도메인이 복잡해 라벨링이 불가능한 환경”에서 반드시 필요한 분석 방법이다.

클러스터링 접근 철학(Philosophy)
- 데이터의 내재적 구조는 사람이 모른다.
- 알고리즘은 ‘비슷한 것의 모임’을 정의하는 방식이 전부 다르다.
그래서 클러스터링을 평가할 때 다음을 고민해야 한다.
- 어떤 거리 척도가 맞는가
- 어떤 스케일링이 필요한가
- 군집 수를 정할 수 있는가
- 고차원에서 군집이 의미 있는가
이 부분은 실제 업계에서 자주 문제 되는 부분이다. “왜 이렇게 묶였나요?”라는 질문이 가장 많다.
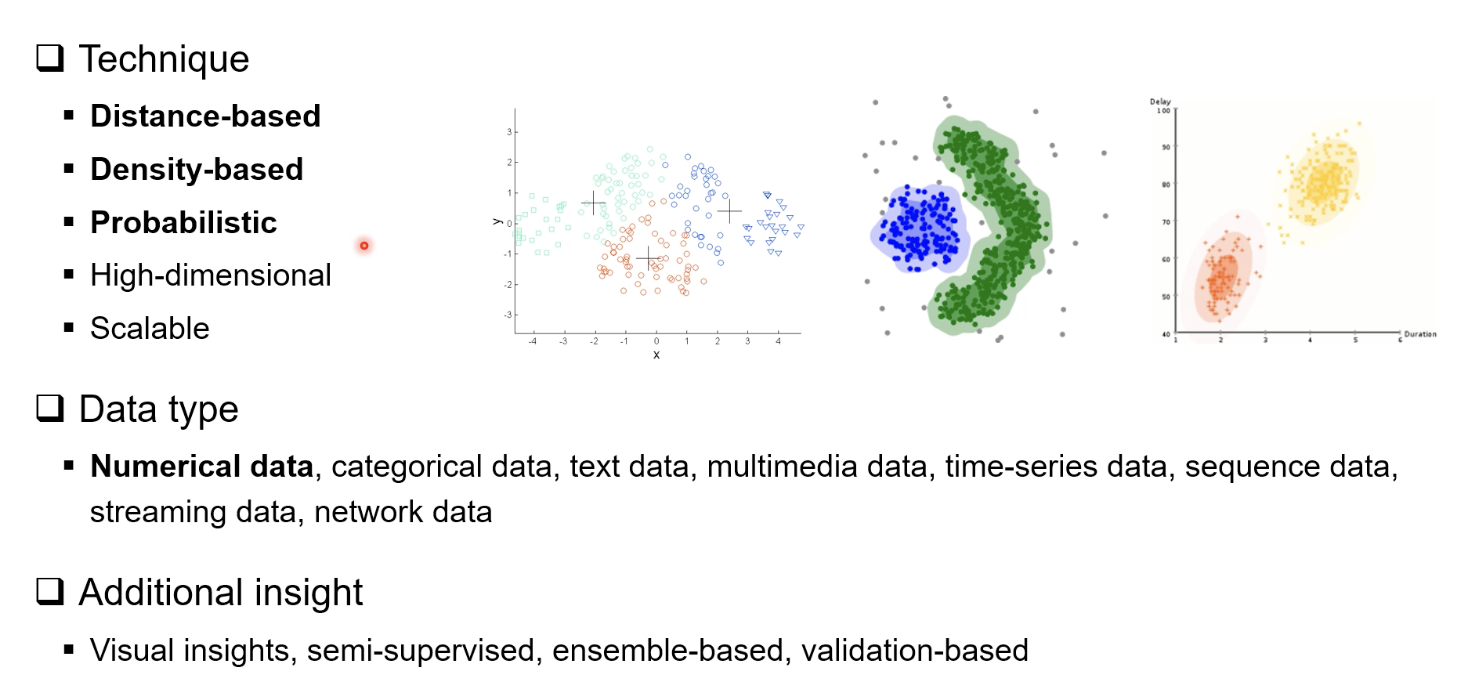
클러스터링 기술
Distance-based (거리 기반) = 대표: K-means, K-medoids
데이터 간 직선 거리(Euclidean)를 기준으로 “가까운 것끼리 묶는다”.
특징:
- 고전적인 방식, 빠르고 확장성 좋음
- 군집이 구 형태로 나올 때 잘 동작
- 초기값(seed)에 민감
산업 예:
- 고객 임베딩을 2차원/10차원에서 K-means로 세그먼트화
- 제품 사용 패턴 구분

Density-based (밀도 기반) = 대표: DBSCAN, HDBSCAN
아이디어는 “밀도가 높은 지역은 군집, 밀도가 낮은 부분은 노이즈 또는 군집 경계”
특징:
- 아무 모양의 군집도 발견 가능
- 군집 수를 자동 결정
- 파라미터 ε(반경), MinPts(최소 이웃 수)가 민감
- 고차원에서는 밀도 개념이 희미해져 성능이 급락 (커서 문제)
산업 예:
- 지도 상 매장의 밀집 지역 탐색
- 임베딩 기반 FAQ 군집화에서 노이즈 문서 제거
- 로그 패턴 중 흔치 않은 anomaly 탐지
Probabilistic (확률 기반) = 대표: Gaussian Mixture Model(GMM)
데이터를 여러 확률 분포(예: 정규분포)의 혼합으로 모델링하고, 각 데이터가 어떤 분포에 속할 확률을 계산한다.
특징:
- “부드러운 할당(soft assignment)” 가능
- K-means보다 유연한 군집
- 분포 가정에 적합할 때 매우 강력
산업 예:
- 고객 행동의 다중 패턴 모델링
- 시간대별 지연 데이터(항공 Delay vs Duration 슬라이드)에서 분포 차이 분석
High-dimensional (고차원 특화) = 대표: Subspace clustering, Spectral clustering
고차원에서 거리, 밀도 모두 무너지므로 새로운 방식이 필요하다.
- 특정 부분 공간(subspace)에서만 군집이 존재
- 그래프 기반(spectral)으로 데이터 구조를 분해
산업 예:
- 텍스트 임베딩(768차원) 군집화
- 사용자 행동 벡터 분석
Scalable Clustering (대규모 데이터) = 대표: MiniBatch K-means, Streaming clustering
엔터프라이즈 환경에서는 수십억 개 데이터를 다룰 수 없으므로, 확장성 있는 방법 사용. Apache Spark MLlib에서도 이 계열을 제공한다.
산업 예:
- 대규모 로그 세그멘테이션
- 광고 트래픽 기반 유사 행동군 분석
클러스터링은 라벨이 없는 데이터에서 내재된 구조를 발견하는 비지도 학습 기법이다.
거리 기반 방법은 유사한 데이터 간 거리에 의존하며, 밀도 기반 방법은 데이터가 존재하는 공간의 밀도를 기준으로 군집을 찾는다.
확률 기반 기법은 데이터가 여러 확률 분포의 혼합으로 생성되었다고 가정하며, 고차원 클러스터링은 차원의 저주를 해결하기 위한 특수한 구조를 활용한다.
계층적 방법은 군집을 단계적으로 통합하거나 분할하여 다양한 granularity의 그룹 구조를 파악할 수 있다.
현업에서는 데이터 전처리, 거리 척도 선택, 군집 수 결정, 고차원 처리, 해석 가능성이 클러스터링의 실제 성공을 좌우한다.
k-Means와 k-Means++의 본질적 차이가 바로 “초기 중심을 어떻게 뽑느냐”에 있다.
둘 다 초기 중심(initial centroids)을 선택한 뒤, 그 다음 과정(할당–업데이트–수렴)은 동일하다. 차이점은 초기 중심을 어떻게 고르는가다.




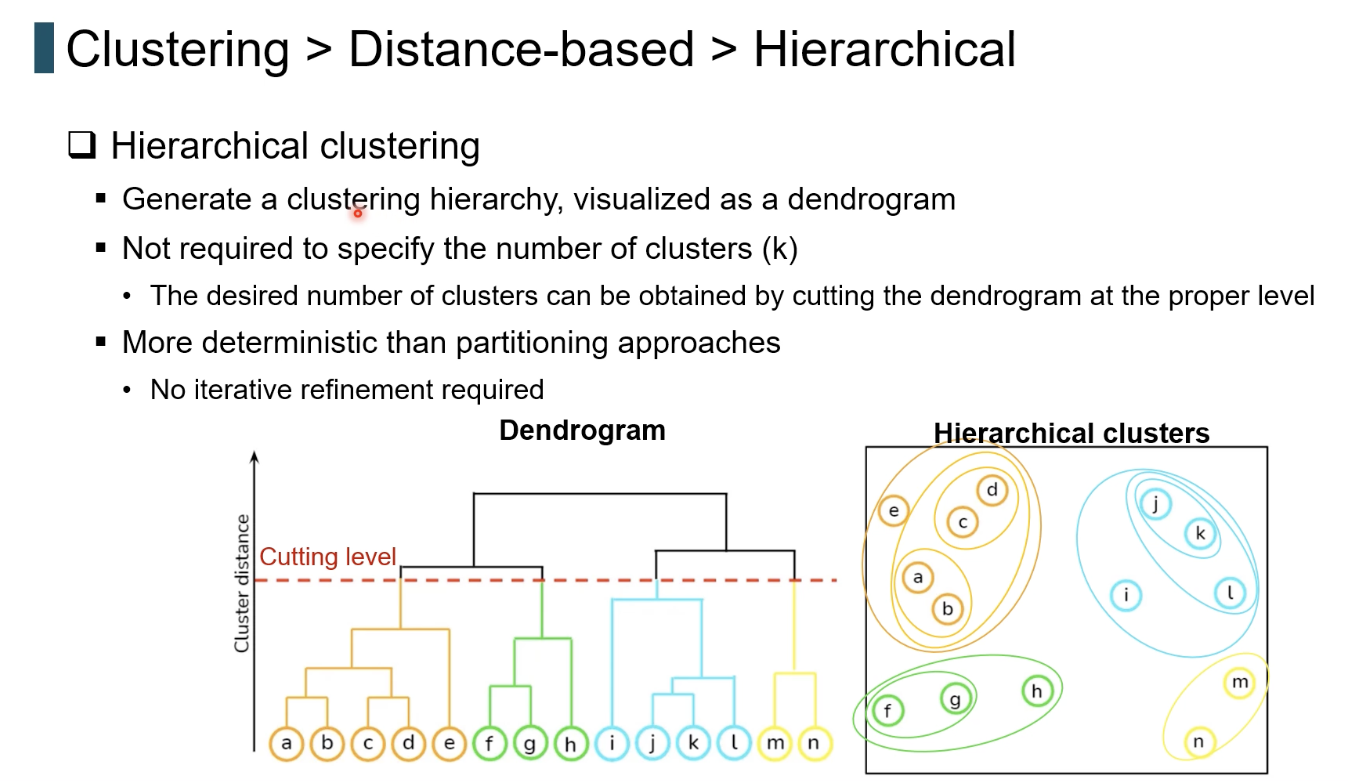
계층적 클러스터링
- 군집 수 k를 사전에 지정할 필요가 없다.
- 데이터 간 유사도를 기반으로 “계층적 구조(트리)”를 만든다.
즉, Partitioning(k-Means, k-Medoids)처럼 “k=5로 나눠!”가 아니라 데이터의 자연스러운 병합 순서를 바텀업으로 만들어서 원한다면 원하는 높이에서 잘라서 클러스터를 얻는 방식이다.
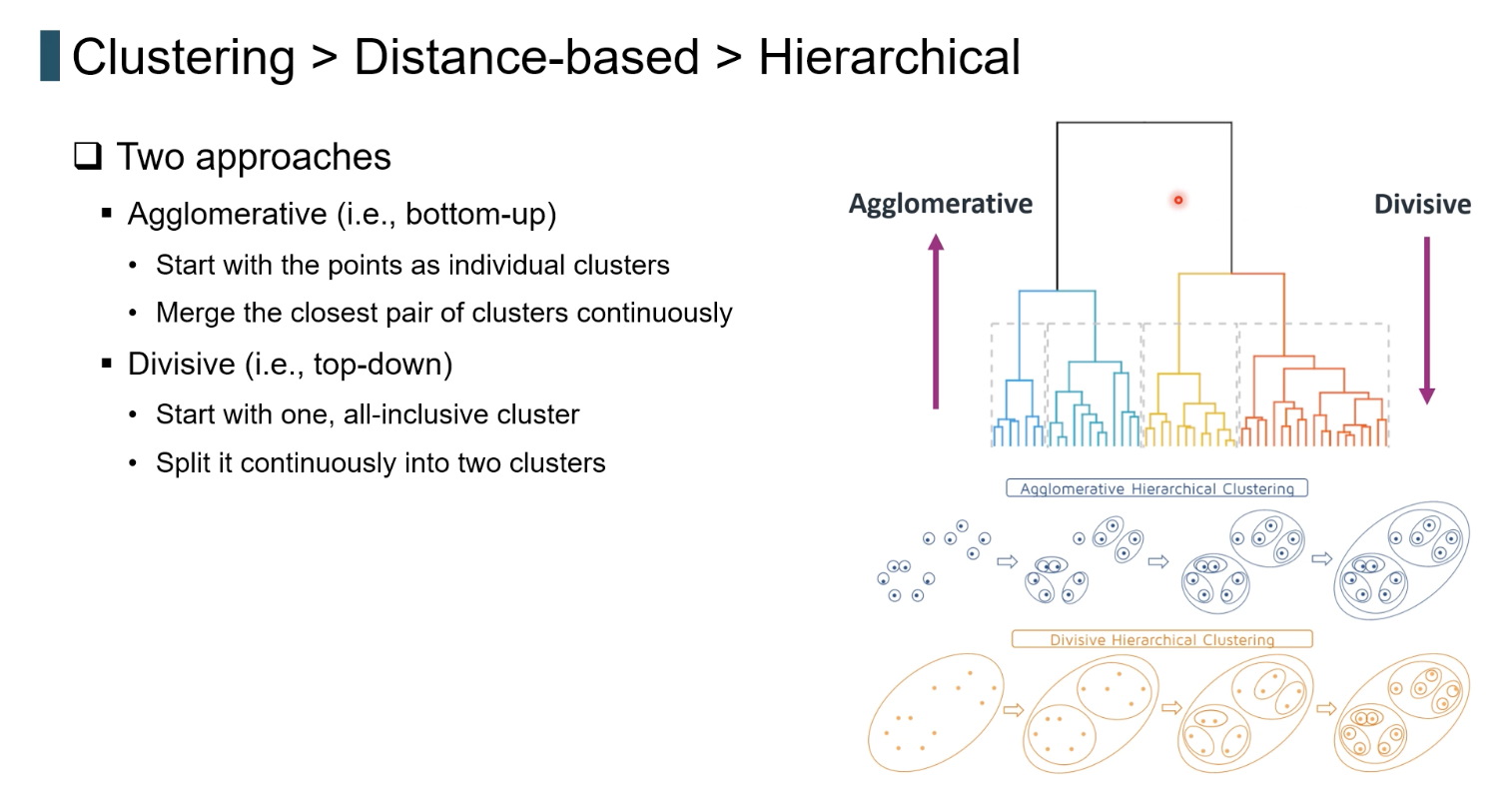
Bottom-up (Agglomerative) 방식이 주는 장점
초기값(seed)에 절대 영향을 받지 않는다
k-Means는 초기 중심값에 따라 결과가 크게 바뀐다. 반면, 계층적 클러스터링은
- 단일 포인트
- 또는 1단계 군집에서 가장 가까운 것부터 순차적으로 병합하기 때문에 완전히 deterministic하다.
다양한 granularity에서 군집을 얻을 수 있다
- 높은 레벨(큰 height)에서 자르면 큰 카테고리
- 낮은 레벨에서 자르면 더 세분화된 그룹
즉, 한 번의 학습으로 여러 수준의 클러스터링 표현을 얻게 된다.
이것은 대규모 문서 색인(RAG·위키 라이크 knowledge base)에서 매우 유용하다.
덴드로그램(Dendrogram)은 무엇인가?
덴드로그램은 “클러스터가 병합되는 순서”를 시각적으로 보여주는 트리 구조다.
- 아래쪽: 개별 데이터
- 위쪽으로 갈수록 군집 간 거리가 커짐
- 어디서 가로줄을 그어 자르느냐에 따라 군집 수가 자동 결정된다
즉, 덴드로그램 = 군집의 생성 과정을 기록한 구조적 지도(structural map)이다.
그럼 어디에 활용하면 좋을까? = 위키! = 계층적 클러스터링이 위키·지식 문서에서 유용한 이유
멀티홉 쿼리(multihop query)의 경우 계층적 군집이 핵심 구조가 된다.
상위 개념–하위 개념 구조를 자연스럽게 표현할 수 있다.
문서 데이터는 계층적 구조를 가진 경우가 많다.
예:
- “광고 정책” → “메시지 규칙” → “금지 어휘”, “심사 기준”
- “예약 기능” → “취소 규칙” → “수수료 정책”
덴드로그램은 이런 구조를 매우 자연스럽게 반영한다.
군집 수를 강제로 정하지 않아도 됨 → 정보 손실이 적다
k-Means처럼 k=10으로 정해버리면
- 중요한 카테고리가 사라지거나
- 서로 다른 개념이 억지로 합쳐질 수 있다.
Hierarchical Clustering은 데이터의 자연스러운 구조를 반영하기 때문에 “사전 군집 수 결정 문제”가 제거된다.
멀티홉 검색(Multi-hop Retrieval)에 최적화된 구조를 제공
“쿼리에서 직접적으로 연관된 문서는 아니지만,
최상위 군집 또는 인접 군집에서 나오는 ‘탑 2 문서’를 함께 불러오고 싶다.”
계층적 클러스터링이 바로 이 문제를 해결한다.
작동방식 예시
- 쿼리 임베딩과 가장 가까운 문서 x를 찾음
- x가 속한 군집을 확인 (덴드로그램에서 x의 위치 파악)
- 해당 군집의 형제 그룹(sibling cluster) 또는 부모 cluster를 탐색
- 그 클러스터 내에서 상위 2~3개의 대표 문서를 Multi-hop retrieval로 추가
이 과정은 “연관이 있지만 직접적으로 검색 점수가 높지 않은 문서”를 논리적인 계층 구조를 기반으로 찾아내는 것이다.
즉, 검색 score 기반 ranking에서 놓칠 수 있는 세밀한 의미적 관계를 계층 구조로 보완한다.
멀티홉 RAG에서 계층적 클러스터링을 쓰면 생기는 효과?
정리하면 다음과 같다.
| 쿼리가 특정 문서를 매칭하지 못함 | 부모/형제 cluster 탐색으로 개념 확장 |
| Multi-hop 탐색 필요 | 덴드로그램 기반 neighbor cluster로 자연스럽게 연결 |
| 문서가 너무 많음 | 군집을 트리 형태로 구분해 탐색 공간 축소 |
| 색인 구조를 자동화하고 싶은 경우 | 덴드로그램이 자동 카테고리 구조를 제공 |
예를 들어,
“메시지 광고 문구 관련 규칙”을 알고 싶은데 쿼리에서는 “문구 제한”이라는 단어가 없을 경우,
해당 문서가 같은 클러스터에 있어도 단순 검색에서는 검색되지 않을 가능성이 높다.
계층 구조를 기반으로 Multi-hop retrieval을 적용하면 상위 cluster를 타고 올라가 관련 문서 더미를 확보할 수 있다.
계층적 클러스터링의 단점도 고려해야 한다
계산 비용이 매우 크다 (O(n²))
n=50,000 문서만 되어도 full hierarchical clustering은 매우 힘들다. 이 경우 다음을 고려해야 한다.
- Sparse matrix 기반 최적화
- Approximate hierarchical clustering
- HDBSCAN 같은 density-based hierarchical 계열
- First-pass clustering(k-means) → local hierarchical clustering
고차원 텍스트 임베딩 공간에서는 linkage method 선택이 매우 중요
- complete linkage
- average linkage
- ward linkage
각 방식에 따라 군집 구조가 달라지며
semantic embedding에서는 average linkage가 가장 안정적인 경우가 많다.
BIRCH 알고리즘이란 무엇인가?
Balanced Iterative Reducing and Clustering Using Hierarchies = “대규모 데이터에서도 계층적 군집을 실시간에 가깝게 만드는 방법”이다. BIRCH는 기본 HAC와 달리 O(n²) 비용이 들지 않도록 설계되었다.
BIRCH의 핵심 개념: CF Tree
BIRCH는 “Clustering Feature Tree(CF-Tree)”라는 요약 구조를 만든다.
각 leaf node에는 실제 data point를 저장하는 게 아니라 군집 통계 요약(summary statistics)만 저장한다.
- N: cluster에 들어온 포인트 수
- LS: linear sum, ∑xi\sum x_i
- SS: squared sum, ∑xi2\sum x_i^2
이 세 정보만 있으면 군집의 center, diameter, radius 모두 다시 계산할 수 있다. = “원본 데이터를 전부 저장하지 않고 요약 정보로 대체하는” 낮은 레벨의 micro-clustering이다.
BIRCH의 절차
Step 1) CF-Tree building (Micro-clustering)
데이터를 하나씩 순차적으로 입력하면서
- 가장 가까운 leaf entry를 찾고
- threshold(최대 diameter) 조건을 만족하면 그 군집에 흡수
- leaf node가 가득 차면 split
이 단계에서 대규모 데이터를 단일 pass(single scan)로 처리할 수 있다.
Step 2) Global Clustering (Macro-clustering)
CF-Tree의 leaf node(=micro clusters)를 대상으로 k-means 같은 빠른 알고리즘으로 high-level 군집을 수행한다.
파라미터 두 개의 의미
(1) Branching factor
각 노드에 들어갈 수 있는 최대 child 수 → 트리 균형도 조절 요소
(2) Threshold
Leaf node 안의 sub-cluster가 허용할 수 있는 최대 지름(diameter) → micro cluster의 크기를 결정
Threshold가 크면 ? = 데이터가 fewer micro clusters로 요약
Threshold가 작으면 ? = 더 세밀한 micro clusters 생성
BIRCH의 장점
- 대규모 데이터에 O(n) 수준으로 동작 가능
전통 계층적 clustering이 O(n²)라 불가능한 환경에서 사용 가능. - incremental / streaming 데이터에 적합
데이터가 한줄씩 들어올 때 CF-tree를 업데이트하며 클러스터링 유지 가능. - 낮은 메모리 footprint
원본 데이터를 다 들고 있을 필요가 없음. = 데이터 군집을 “수백만 개의 점”이 아니라 "통계 요약(statistical summary)"로 표현한다.
BIRCH의 단점
1) Insertion order sensitive
데이터가 들어오는 순서에 따라 CF-tree 구조가 달라진다.
2) Leaf node 크기가 고정되어 클러스터가 자연스럽지 않을 수 있음
Threshold를 기계적으로 맞추기 때문에 데이터의 실제 semantic 분포와 어긋날 수 있음.
3) Clusters가 spherical 형태로 제한
micro clustering에서 diameter 기반으로 관리한다는 것은 결과적으로 구 형태 cluster를 전제로 한다는 의미다.
문서 임베딩 같이 복잡한 manifold에서는 한계가 있다.
BIRCH, 그럼 언제 유용한가?
유용한 경우
- 초대규모 데이터 (예: 1M ~ 100M 포인트)
- 온라인/스트리밍 처리
- 로그/센서 데이터 단순 요약
- “대략적인” clustering 필요
- 이후에 k-means 등 빠른 알고리즘을 위해 데이터 압축할 때
유용하지 않은 경우
- 문서/이미지 embedding처럼 복잡한 semantic structure
- 비선형, 긴 cluster, manifold shape
- 고품질 군집 필요
- hierarchical topic clustering 같은 해석 기반 작업

BIRCH는 데이터를 CF-tree라는 요약 구조(N, LS, SS)로 압축한 뒤, 이 요약된 micro-cluster에 대해 최종 클러스터링을 수행하는 ‘대규모 데이터 전처리형 클러스터링 모델’이며, threshold·leaf 크기·삽입 순서 때문에 실제 데이터 분포를 왜곡할 수 있다는 근본적 한계를 가진다.
'ML&AI' 카테고리의 다른 글
| agentic-patterns.com - Memory (0) | 2026.01.11 |
|---|---|
| 대화 히스토리를 기반으로 이미 확보된 정보와 남은 불확실성을 구분하고,fallback 상황에서 정보 획득을 극대화하는 질문 정책을 학습할 수 있는가? (0) | 2026.01.04 |
| Classification – Decision Tree, GINI, Entropy, Impurity, Gain Ratio (1) | 2025.12.14 |
| 데이터를 해석하고 결정을 내리는 알고리즘: Classification의 개념, 방법론, 그리고 분할 기준 (1) | 2025.12.13 |
| 왜 고차원 데이터에서 아웃라이어 디텍션이 어려운가? -> 딥러닝 기반 Outlier Detection (0) | 2025.12.13 |