“정보를 더 많이 얻는다”
결정트리에서 정보(information) 라고 부르는 건 철학적인 “지식”이 아니라, 레이블에 대한 불확실성(uncertainty) 이 얼마나 줄어드는가를 말한다.
- 어떤 고객이 Defaulted = Yes/No 인지 우리가 얼마나 모르는 상태인지
- 그 “모름”의 양을 수치로 표현한 것이 엔트로피(Entropy) 나 지니(Gini) 같은 불순도(impurity) 이고
- 어떤 속성으로 split 했을 때
- split 전 불순도 − split 후 불순도
- 즉, 불확실성이 얼마나 줄어들었는가가 정보 이득(Information Gain) 이다.
그래서
- “정보를 더 많이 얻는다” = “레이블에 대한 불확실성이 더 많이 줄어든다”
- 즉, split 이후에 “이 노드에 들어온 애들은 거의 다 Yes야” 혹은 “거의 다 No야” 하고 확신할 수 있게 되는 정도가 커졌다는 뜻이다.
결정트리에서 쓰는 주요 개념들 큰 그림
결정트리에서 노드를 나눌 때 항상 하는 질문은 하나다.
“어떤 속성으로, 어떻게 나눌 때 자식 노드들이 더 ‘깨끗해질까’?”
여기서 “깨끗하다”는 뜻이 바로 불순도가 낮다(impurity ↓) 이고, 이것을 수식으로 표현하는 여러 방법이 있다.
- 엔트로피(Entropy)
- 결과를 알기 전에 평균적으로 얼마나 많은 정보가 필요한가를 말한다. p가 0,1일때 엔트로피0이다. 즉 엔트로피가 0 또는 1이면 노드 결과 예측에 확실하다는것을 의미한다.
- 스필릿전후의 엔트로피의 차이를 information Gain으로 정의한다.
- 지니 지수(Gini index)
- 위 둘을 이용한 불순도(impurity) 개념
- 한 노드 안에 여러 클래스가 섞여 있는 정도를 숫자로 표현한것이다. 섞여 있을수록 불순 -> 불순도 값이 크다. -> 트리의 목표는 비슷한 애들끼리 모여있는 리프를 만드는 것이다. 따라서 스플릿 기준은 자식 노드들의 불순도를 얼마나 낮출수 있는가를 기준으로 선택해야 한다. 불순도를 구체적으로 어떻게 정의하느냐에 따라 엔트로피 기반트리 / 지니기반 트리등 알고리즘이 갈린다.
- 정보 이득(Information Gain) / Gini Gain
- 게인 레이시오(Gain Ratio)
- 단순히 엔트로피가 얼마나 줄었나? Gain만 보면 값 종류가 많은 속성으로 잘게 쪼갤수록 Gain이 커져버린다.
- Gain Ratio는 그 Gain이 얼마나 복잡한 분할등을 통해 얻어진 것인지를 보정한다.
- SplitInfo가 크다 = 노드를 너무 잘게 쪼갰다 = 분모가 커지면서 GainRatio를 깎는다.
이제 각 개념을 하나씩, “의미·언제 쓰는지·좋은 값의 방향”까지 정리해보자.



엔트로피: 여러 가능한 사건의 ‘평균 정보량’
어떤 확률변수 X 전체가 갖는 평균적인 불확실성을 측정하고 싶다고 하자. 이때 사용하는 개념이 바로 엔트로피(Entropy)다.
확률변수 X가 취할 수 있는 값이 {x₁, x₂, …, xₖ}이고, 각각의 확률이 P(X = xⱼ) = pⱼ라면, 엔트로피 = 이 값은 “X의 결과를 알기 위해 평균적으로 얼마나 많은 정보(비트)가 필요한지”를 의미한다.
다시 말해, X가 얼마나 예측하기 어려운지, 즉 불확실성(uncertainty)이 얼마나 큰지를 수치로 나타낸 값이다.
엔트로피의 중요한 성질은 다음과 같다.
- 모든 확률이 0 또는 1인 완전 확실 상태에서는 엔트로피가 0이다. = 이미 결과를 알고 있으므로 더 이상 얻을 정보가 없다.
- 확률이 가장 균등하게 분포될수록 엔트로피가 최대가 된다.
예를 들어, 두 클래스가 50:50인 이진 분류 문제에서 엔트로피가 가장 크다. 어떤 결과가 나올지 가장 예측하기 어렵기 때문이다.
노드의 엔트로피: 결정트리에서의 불순도 측정
이제 이 개념을 결정트리(Decision Tree)로 옮겨보자.
결정트리에서는 각 노드에 여러 개의 데이터 포인트가 들어오고, 각 데이터는 특정 클래스 라벨을 가진다.
이때 그 노드가 얼마나 순수(pure)한지, 혹은 얼마나 클래스가 섞여 있는지(impure)를 측정하기 위해 엔트로피를 사용한다.
어떤 노드 t가 있고, 그 안에 클래스 j가 등장할 확률을 p(j∣t)p(j|t)라고 하자.
이 값은 단순히 p(j∣t) = 노드 안에서 해당 클래스가 차지하는 비율이다.
이때 노드 t의 엔트로피는 다음과 같이 정의된다.
Entropy(t)= “노드 t에 있는 데이터의 라벨을 맞추기 위해 평균적으로 얼마나 많은 정보가 필요한가”를 의미한다.
따라서 엔트로피가 클수록 노드 안의 클래스들이 섞여 있어 불확실성이 크고, 엔트로피가 0에 가까울수록 한 클래스가 지배적이라서 불확실성이 작다.
노드 엔트로피 예시: Yes 1개, No 5개인 노드
슬라이드의 예시는 노드 N에 데이터 6개가 있고,
그 중 1개는 Yes(파란색), 5개는 No(초록색)인 상황이다.
- P(Yes | N) = 1/6
- P(No | N) = 5/6
각 클래스의 정보량은 다음과 같이 계산된다.
- Yes에 대한 정보량:I(Yes)=−log2(1/6)≈2.58I(Yes) = -\log_2 (1/6) \approx 2.58
- No에 대한 정보량:I(No)=−log2(5/6)≈0.26I(No) = -\log_2 (5/6) \approx 0.26
즉, “이번 샘플이 Yes였다”는 사실은 꽤 놀랍기 때문에 정보량이 크고, “이번 샘플이 No였다”는 사실은 비교적 자주 나오는 결과라 정보량이 작다.
노드 전체의 엔트로피는 각 클래스의 확률로 가중평균을 내서 계산한다.
Entropy(N)
이 값은 “노드 N에서 임의의 샘플을 하나 뽑았을 때, 그 라벨을 알게 되면 평균적으로 약 0.649 비트의 정보를 얻게 된다”는 의미다.
또는 “이 노드의 라벨은 완전히 확실하지는 않지만, 완전히 혼합되어 있지도 않다” 정도로 해석할 수 있다.
결정트리에서 엔트로피를 사용하는 이유
결정트리는 각 단계에서 데이터를 어떻게 분할할지를 선택해야 한다. 이 선택 기준이 바로 엔트로피 감소량(Information Gain) 이다.
불순도(= 엔트로피)를 ‘최소화’하는 split을 선택하는 것이 목적이다.
- 먼저 현재 노드의 엔트로피를 계산한다.
- 어떤 속성으로 분할했을 때 하위 노드들의 엔트로피를 각각 계산하고,
하위 노드의 크기(샘플 수)를 가중치로 사용해 가중 평균 엔트로피를 구한다. - “부모 노드의 엔트로피 − 자식 노드들의 가중 평균 엔트로피”가 바로 정보 이득이다.
- 정보 이득이 가장 큰 속성을 split 기준으로 선택한다.
- 엔트로피 ↓
- 순수도 ↑
- 분류 성능 ↑
- 좋은 의사결정 split
이 과정은 직관적으로 다음과 같이 이해할 수 있다.
- 분할을 통해 라벨에 대한 불확실성이 얼마나 줄어들었는가를 측정하고,
- 불확실성을 가장 많이 줄여주는 속성을 선택한다.
엔트로피가 낮을수록 좋다. = 특히 0이면 가장 좋은 상태이다.
엔트로피 0
- 모든 샘플이 같은 클래스
- 불확실성 없음
- 가장 이상적인 leaf node
엔트로피가 1(이진 분류의 경우 최대값)
- Yes 50%, No 50%
- 가장 예측하기 어려운 상태
- 불순도 최고
- split이 절실히 필요한 상태
즉, 엔트로피 = 불확실성 는 결정트리가 “데이터를 가장 잘 설명해주는 질문을 순차적으로 골라가도록 만드는 핵심 척도”인 셈이다.


결정트리에서 Information Gain의 한계와 Gain Ratio가 필요한 이유
결정트리에서 분할 기준을 고를 때 가장 널리 사용하는 지표가 Information Gain(정보 이득)이다.
문제는, 이 지표가 “순수도가 극단적으로 높아지는 분할”, 즉 작은 조각으로 잘게 쪼개는 split을 지나치게 선호하는 경향이 있다는 점이다.
이 현상은 특히 카테고리 값(card number 등)이 매우 다양할 때 두드러진다.

Gain Ratio는 “불순도 감소량(Gain)”과 “분할 복잡도(SplitInfo)”를 함께 고려해, 가장 의미 있게 정보를 제공하는 split을 선택하는 기준이다.
- Split을 몇 개 그룹(k partitions)으로 나눌지 기준은 무엇인가?
- Gain Ratio가 ‘정보를 더 많이 얻는 기준’을 어떻게 판단하는가?
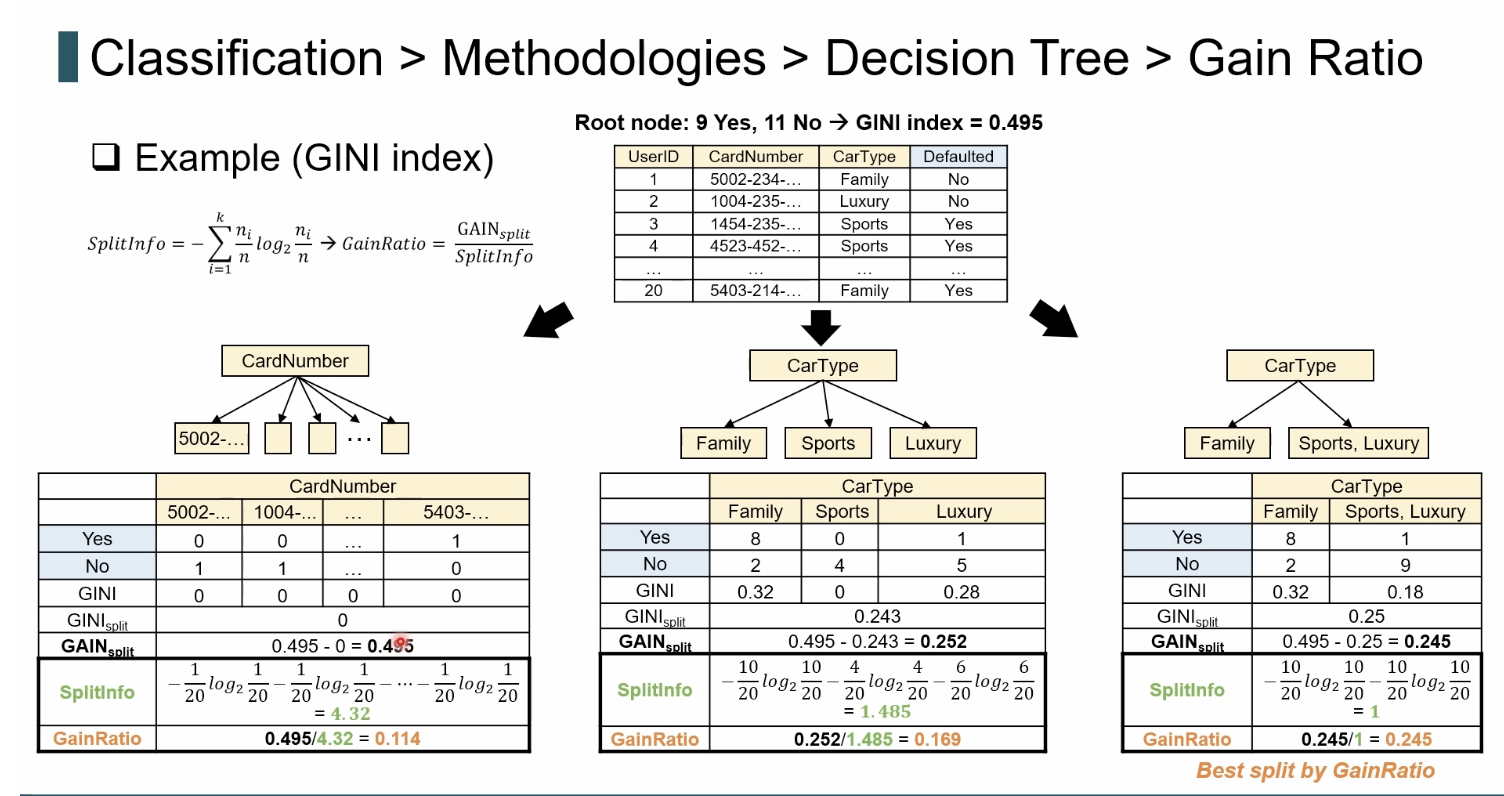
결정트리는 하나의 속성이 가지는 카테고리 개수(k) 만큼 자연스럽게 자식 노드를 생성한다. 예시에서 CarType = {Family, Sports, Luxury} 이므로 split 하면 3개의 가지가 생긴다. 반면 CardNumber처럼 값이 20개 모두 다르다면
- → 20개의 자식 노드가 생기는 split이다.
- → 이것이 Information Gain 기준에서는 문제를 일으킨다.
“Gain Ratio는 더 많은 정보를 얻을 수 있는 기준으로 나누는 건가?”
정확히 말하면 ‘정보이득을 보정하여, 의미 있는 분할을 선택하는 것’이다.
- 정보이득(GAINsplit) — 얼마나 불순도가 줄었는가?
- CardNumber split: GAIN = 0.495 / CarType split: GAIN = 0.252여기까지만 보면 CardNumber가 압도적으로 좋아 보인다.그러나 이는 과적합을 일으키는 가짜 이득이다.
- “분할이 얼마나 복잡하게 흩어졌는가?”
- 자식 노드가 많고, 각 노드의 사이즈가 비슷하게 매우 작게 퍼져 있으면
→ SplitInfo 엔트로피가 매우 높아짐 → 즉 “너무 많은 가지를 강제로 만든 split”이라고 해석한다.- CardNumber의 SplitInfo = 4.32 (매우 높음)
- CarType의 SplitInfo = 1.485 또는 1 (낮음) 예시에서 이 차이는 엄청 크다.
- 자식 노드가 많고, 각 노드의 사이즈가 비슷하게 매우 작게 퍼져 있으면
- 따라서 GainRatio는 다음을 평가한다.

| 개념 | 직관적 의미 | 목적(왜 쓰는가) | 좋은 값의 방향 | 언제 사용되는가 (알고리즘/상황) |
| Impurity (불순도) | 한 노드 안에 클래스가 섞여 있는 정도 | Split 후 자식 노드의 순수도를 평가하는 기준 | 낮을수록 순수함(0이 이상적) | 모든 결정트리에서 공통적으로 사용되는 개념적 프레임 |
| Entropy (엔트로피) | 불확실성(uncertainty)의 양. 반반이면 최대, 한쪽이면 0 | 레이블의 불확실성을 정확하게 측정 | 낮을수록 good (0이 완전 순수) | ID3, C4.5, 정보이론 기반 트리, 시험 문제에서 자주 등장 |
| Gini Index (지니 지수) | 임의 두 샘플을 뽑았을 때 서로 다른 클래스일 확률 | 불순도를 단순·빠르게 계산 | 낮을수록 good | CART, scikit-learn DecisionTreeClassifier의 기본 옵션 |
| Information Gain (정보 이득) | Split 후 불확실성이 얼마나 줄었는지 = 얻은 ‘정보량’ | 가장 불순도 감소가 큰 split 선택 | 클수록 good | ID3, C4.5, 엔트로피 기반 트리. 단, 고카디널리티 속성에 취약 |
| Gini Gain (지니 이득) | Gini 기준의 불순도 감소량 | 가장 Gini 감소가 큰 split 선택 | 클수록 good | CART 기반 트리(sklearn 기본) |
| SplitInfo (스플릿 정보) | 자식 노드 크기 분포의 엔트로피. 노드를 얼마나 많이 쪼갰는가 | 너무 많은 조각으로 split되는 속성에 페널티 | 값이 클수록 “과도하게 분할됨” | C4.5에서 Information Gain 보정용으로 사용 |
| Gain Ratio (게인레이시오) | split의 효과를 분할 복잡도로 정규화한 지표 | 과도한 분할(예: ID, CardNumber)을 억제하고 의미 있는 split 선택 | 클수록 good(단, Gain이 일정 이상일 때 사용 권장) | C4.5 결정트리. 고카디널리티 속성 존재 시 매우 중요 |