챗봇이나 대화형 에이전트에서 사용자의 의도(Intent) 를 분류하는 과정은 본질적으로 “입력 문장을 사전에 정의된 클래스 중 하나로 분류하는 문제”다. 이 작업을 구현하는 방법은 크게 두 가지로 나뉜다.
(1) 전통적 분류 기반 접근
전통적인 방식에서는 지도학습(Supervised Learning) 구조를 사용한다.
즉, 대화 데이터에 대해 각 문장이 어떤 인텐트에 해당하는지 명시적으로 레이블링(labeling) 하고, 이 데이터를 이용해 분류 모델을 학습한다.
이때 사용되는 모델은 다음과 같이 다양하다.
- Logistic Regression, SVM, MLP 등 고전적인 분류기
- BERT나 SBERT 같은 사전학습(Pre-trained) 언어모델을 임베딩 생성기(feature extractor) 로 활용한 후, 분류 레이어(Softmax classifier)를 얹은 형태
- 혹은 단순히 문장 임베딩 간의 코사인 유사도를 계산해, 기존 인텐트 예시 중 가장 가까운 의도를 선택하는 방식
이 방법의 특징은 명시적인 라벨 기반 학습을 한다는 점이다. 모델은 특정한 의도들을 구분하기 위해 파라미터를 조정하고, 학습이 끝난 뒤에는 일관된 기준으로 입력을 분류한다. 다만, 새 인텐트가 추가되거나, 문체가 달라지면 모델을 다시 학습해야 한다는 단점이 있다.
이 방식은 비교적 비용이 낮고, 속도가 빠르며, 예측 결과가 일관적이다. 하지만 문장 간 의미적 유사도에 의존하기 때문에, 언어적 다양성이나 암시적인 표현, 맥락을 해석하는 능력은 약하다. 예를 들어 “내일도 이 시간에 해요?” 같은 문장이 사실상 ‘예약 문의’이지만, 데이터셋에 비슷한 표현이 없으면 잘못 분류될 수 있다.
(2) LLM 기반의 프롬프트 추론 접근
GPT 계열의 대형언어모델(LLM)을 활용하는 경우에는, 모델이 명시적으로 분류기를 학습하는 대신, 프롬프트(prompt) 안에서 “의도를 선택하라”는 지시를 통해 분류를 수행하게 된다.
예를 들어 다음과 같은 식이다.

모델은 내부적으로 각 선택지와 입력 문장의 의미적 관계를 파악하고, 그 중 가장 합리적인 결과를 출력한다.
즉, 기존 분류기가 확률 분포 P(y∣x)를 계산해 가장 높은 클래스를 고르듯이, LLM도 자연어 추론(natural language inference) 과정을 통해 가장 일관된 선택지를 “생성”하는 것이다.
이 접근법의 장점은 데이터를 직접 학습시키지 않아도 된다는 점이다. 프롬프트만 잘 설계하면 Zero-shot 또는 Few-shot 방식으로도 의도 분류가 가능하다.
그러나 프롬프트만으로 원하는 수준의 일관된 결과를 얻기 어려운 경우, 결국 LLM을 파인튜닝(fine-tuning) 하거나 의도 데이터셋을 기반으로 추가 학습(Instruction tuning, DPO 등) 해야 한다.
이 경우, 사실상 전통적인 분류 모델을 학습하는 것과 유사한 형태가 된다.
즉, “LLM에 데이터를 넣고 학습시킨다”는 행위는 결국 “특정 태스크(여기서는 인텐트 분류)를 위한 지도학습”이라는 점에서 동일한 본질을 가진다.
학습 방식은 다르지만, 목적은 같다
두 방식은 모두 사용자의 발화를 특정 의도로 매핑한다는 점에서 같지만, 일반화와 추론의 방식이 다르다.
- 전통 분류 모델은 “의도 = 학습된 결정경계”로 정의한다. 데이터로부터 구체적인 분류 기준을 학습해, 이후 입력이 들어오면 해당 기준으로 결과를 낸다.
- 반면 LLM은 “의도 = 언어적 의미 관계”로 이해한다. 기존 데이터와의 단순 유사도보다는, 문장 의미의 함의 관계를 추론하는 방식으로 판단한다.
그렇기 때문에 LLM은 보지 못한 표현이나 새로운 조합에 강하고, 전통 분류기는 반복적으로 검증된 패턴에는 일관성이 높다.
성능과 비용의 균형
비용과 안정성 관점에서 보면, 두 접근법은 서로 상반된 특성을 가진다.
| 관점 | 전통 분류 모델 | llm 기반 분류 |
| 학습 비용 | 초기 학습 필요, 하지만 이후 유지비 저렴 | 프롬프트만으로도 가능하지만, 세밀 제어에는 재학습 필요 |
| 추론 비용 | 매우 낮음 (ms 단위) | 상대적으로 높음 (초 단위, API 비용 발생) |
| 일관성 | 높음 (결정경계 고정) | 낮음 (LLM의 생성적 특성, 답변 변동 가능) |
| 해석력 | 명확한 피처 중요도 파악 가능 | 자연어 추론으로 인해 설명 어려움 |
| 확장성 | 새 인텐트 추가 시 재학습 필요 | 프롬프트 수정만으로 확장 가능 |
| 표현력 | 문자적 유사도 중심 | 의미적/맥락적 추론 가능 |
결국 “데이터 규모와 유연성의 필요 정도” 가 선택의 기준이 된다.
데이터가 충분하고 인텐트 구조가 안정되어 있다면 전통적인 분류기(BERT fine-tuning, SBERT + classifier)가 훨씬 효율적이다.
반면, 인텐트가 자주 바뀌거나 언어적 변주가 많고, 사용자의 의도를 명시적으로 분류하기 어렵다면 LLM의 프롬프트 기반 접근이 적합하지 않을까 생각이 든다. (뭐 초기 오픈하는 상황이 될수도 있다. 확보된 데이터가 많지 않은 경우)
단일 발화 분류” vs “대화 맥락 기반 분류”
보통 인텐트 분류라고 하면,
“하나의 사용자 문장(utterance)” → “하나의 의도(intent)”
이렇게 1:1 매핑으로 훈련합니다.
하지만 실제 대화에서는 사용자의 의도가 이전 발화와의 관계에 따라 달라진다.

마지막 문장만 보면 단순히 “예약 언급”이지만,
앞선 대화가 없으면 “식당 예약”인지 “회의 일정 확정”인지 구분하기 어렵다. 이때 필요한 게 바로 대화 컨텍스트(context) 학습이다.
BERT 계열 로는 못하나? BERT 모델이 처리하는 방식
BERT 자체는 단일 문장 분류에 최적화되어 있다. 하지만 대화 히스토리를 입력으로 주는 방법이 두 가지 있다.
(1) Concatenation 방식
이전 대화들을 모두 하나의 입력으로 이어붙여서 넣는다 . 스페셜토큰으로 구분해서 이전대화와 현재 대화를 구분하면 된다.
[CLS] 유저: 내일 점심 괜찮아요? [SEP] 상대: 네 괜찮아요 [SEP] 유저: 그럼 예약해둘게요 [SEP]
기존 BERT분류 헤드를 그대로 사용가능하나 토큰제한 (512토큰)등에 걸리고, 긴대화에서는 앞부분이 손실된다. 즉 이 방식은 짧은 대화에는 유효하지만 긴 세션이라면? 한계가 있다.
(2) Hierarchical BERT (계층적 인코딩)
이전 발화 하나하나를 BERT로 인코딩하고, 그 결과를 상위 RNN, GRU, Transformer에 넣어서 대화 단위로 모델링한다.

이 방식은 이 “Contextual Intent Classifier” 또는 “Hierarchical Dialogue Model”이라고 부른다.
이 모델은 문장 간 순서, 화자 교대(turn-taking), 이전 응답 등을 학습해
“지금 발화가 어떤 흐름에서 나왔는가”를 이해하는것을 말한다.
LLM(GPT 계열)이 처리하는 방식
LLM은 구조상 이미 “문맥을 통한 의미 추론”이 기본값이다.
즉, 별도의 계층 모델을 만들 필요 없이, 프롬프트에 히스토리를 포함해서 사용하게 된다.

GPT는 앞선 문맥을 해석하고, 자연스럽게 2번 ‘식당 예약’ 을 선택할 수 있다.
이건 모델이 “히스토리 전체를 토큰 시퀀스로 처리하는 언어모델”이기 때문에 가능한 일이라고 볼수있다.
즉, BERT는 명시적으로 “이전 문맥을 포함시켜줘야” 하지만, LLM은 문맥을 그대로 넣으면 추론 과정에서 자동으로 반영된다.
따로 비교를 해보진 않았고 실무경험이랑 알고 있는 내용 기반으로 정리를 해봤다. 어떤 방법론이 더 적합한지 다루고 있는지 논문은 딱히 안보이는거 같기도 하다.
어느 쪽이 우세한가?
컨텍스트를 반영해야 하는 대화 인텐트 분류라면, LLM이 구조적으로 유리하지만 항상 실용적이지는 않다.
- LLM의 강점
- 문맥 이해, 발화 간 관계 해석, 모호한 표현 처리에 탁월
- 별도 구조 설계 없이 히스토리를 자연어로 넣으면 작동
- few-shot으로도 좋은 결과 가능
- BERT 기반의 강점
- 훨씬 빠르고 비용이 저렴
- 일관성 높고 예측 결과가 안정적
- 일정 길이 이내의 히스토리만으로도 충분히 높은 정확도 달성 가능
따라서 보통은 하이브리드 형태로 구성한다.
- BERT 기반 classifier 로 빠르고 일관된 intent 분류를 수행하고,
- 불확실하거나 복합적인 경우에만 LLM을 후처리(post reasoning) 로 사용한다.
이게 가장 합리적인거 같다. 주로 FAQ에 해당하는건 버트 기반으로 이외 폴백이나 복합한 경우에는 LLM으로 보조 추론하는 혼합형이 가장 합리적인거 같긴 하다. (이유는 비용과 일관성 문제 때문이지뭐..는 틀에서 못벗어나서인가 ㅎ)
분류는 '무엇인가'를 구분하는 일이다.
그리고 모든 지능형 시스템의 출발점이다. 입력을 명확히 구분할 수 있어야 다음 행동을 설계할 수 있다. 단순한 분류 모델이든, 대규모 언어모델을 통한 의미 기반 판단이든, 결국 목적은 “더 나은 의사결정”을 위한 경계를 그어주는 일이다. (앞에쓴 인텐트 뿐만 아니고도 여러곳에서 쓰인다.)
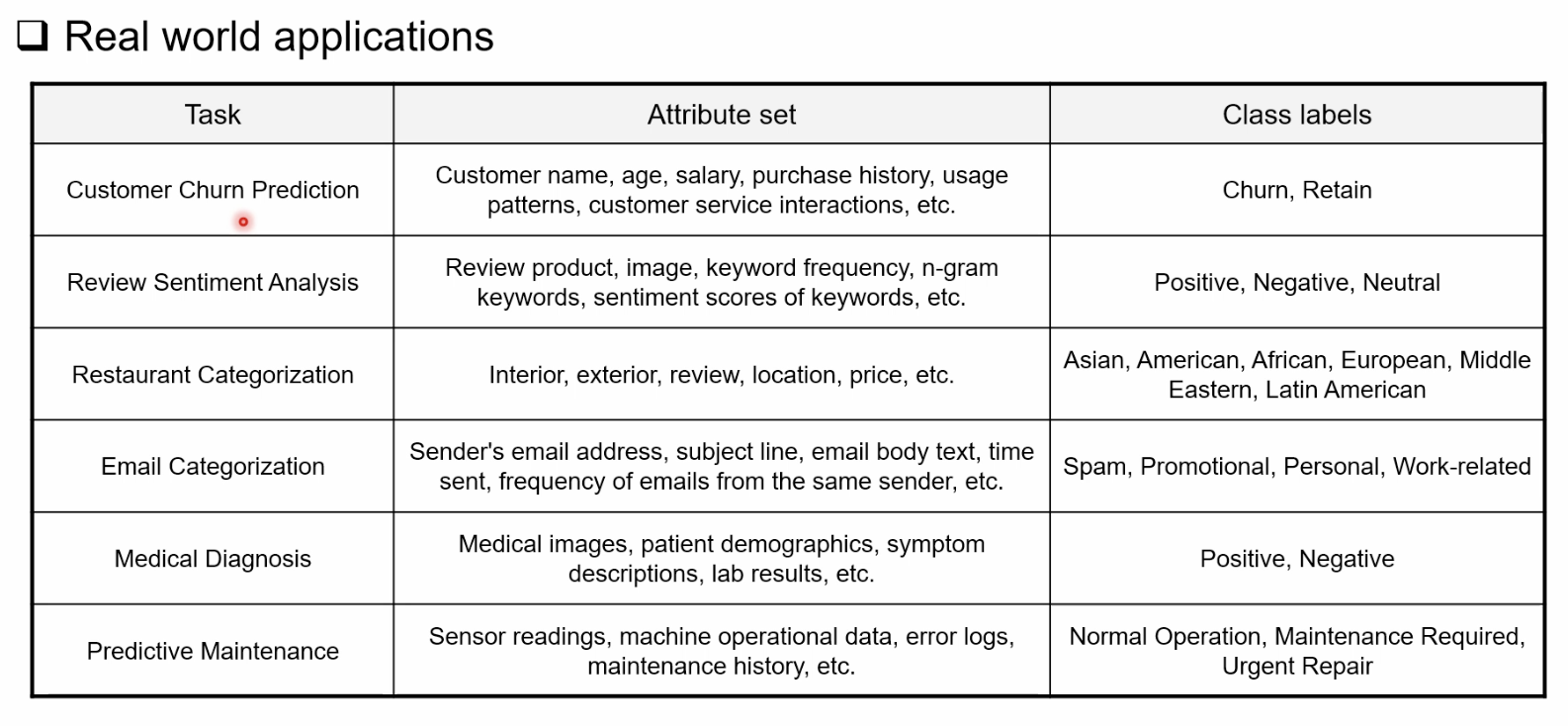
입력, 라벨로 매핑하는 지도학습 문제이다. 보통 확률 P(y∣x)를 모델링하고, 최종 예측은 가장 그럴듯한 클래스를 고르는 형태다.
- 입력 예: 텍스트(리뷰), 이미지, 사용자 로그, 센서 값…
- 라벨 예: 긍정/부정, 스팸/일반, 카테고리, 토픽 등
| Binary classification (이진 분류) | 두 개 클래스 중 하나 예측 | 긍정/부정, 스팸/햄, 합격/불합격 출력: 시그모이드, 임계값 t 넘으면 1. |
| Multi-class classification (다중 클래스 분류) | 여러 클래스 중 하나 예측 | 음식 종류: 한식/중식/양식, 감정: 기쁨/슬픔/분노 출력: 소프트맥스, max로 결정. |
| Multi-label classification (다중 라벨 분류) | 한 데이터가 여러 클래스 동시에 가질 수 있음 | 영화 장르: 액션+코미디, 광고 문장: “할인”+“리마인더” 출력: 클래스별 시그모이드 + 클래스별 임계값. |
그밖에..
|
파이프라인은 대강 아래와 같다.
- 문제 정의 & 라벨링 스킴
- 클래스 집합 정의, 다중 라벨 여부, 평가 지표 합의.
- 데이터 준비
- 라벨 품질 점검, 분포/불균형 파악, 누락·중복 처리.
- 전처리 & 피처화
- 표 형식: 스케일링, 원-핫 인코딩, 파생변수.
- 텍스트: 토크나이징 → TF-IDF 또는 임베딩(BERT 등).
- 이미지/음성: 표준화/증강.
- 모델 선택
- 선형: 로지스틱 회귀(빠르고 해석 용이)
- 트리/앙상블: RandomForest, XGBoost(강력한 기본기)
- 마진 기반: SVM(결정 경계가 깔끔)
- 인스턴스 기반: kNN(베이스라인·소규모)
- 신경망/트랜스포머: CNN/LSTM/BERT(텍스트 SOTA)
- 학습(훈련)
- 손실: Binary/Multi-class → BCE, CE
- Multi-label → BCE(클래스별 독립), 필요 시 Focal Loss(불균형)
- 클래스 가중치/리샘플링(SMOTE 등)로 불균형 보정.
- 임계값/결정정책
- Binary: 0.5 고정 대신 PR-AUC 기준 최적 임계값 탐색.
- Multi-label: 클래스별 다른 임계값, Top-k 선택 등.
- One-vs-Rest/One-vs-One 전략(특히 SVM).
- 평가
- 혼동행렬, Accuracy, Precision/Recall/F1(마이크로/매크로),
- ROC-AUC vs PR-AUC(희소·불균형일 때 유리),
- Multi-label: 샘플/라벨 마이크로·매크로 F1.
- 캘리브레이션(Platt/Isotonic)으로 확률 신뢰도 개선.
- 오류 분석 & 해석
- 오분류 사례 점검, SHAP/특징중요도로 원인 파악,
- 데이터/라벨 보강 루프.
- 배포 & 모니터링
- 추론 지연, 비용, 스케일, 데이터/모델 드리프트 감시,
- 재학습 주기/액티브 러닝 설계.
'ML&AI' 카테고리의 다른 글
| JSON / Function-Call 기반 스트럭처드 아웃풋은 응답시간(latency)과 토큰 비용이 확실히 증가하는 경향이 있다. (0) | 2025.11.03 |
|---|---|
| 이미지를 이해하는 신경망의 눈: 스케일, 바운딩박스, 그리고 NMS (0) | 2025.10.30 |
| 데이터의 구조를 모델이 이해한다는 것, CNN은 왜 시각 피질을 닮았을까 — CNN의 철학 (0) | 2025.10.30 |
| 패턴마이닝 : Support, Confidence, Lift로 보는 연관규칙: 데이터 속 숨은 관계를 해석하는 법 (0) | 2025.10.22 |
| Data Augmentation vs. Built-in Invariance (0) | 2025.10.16 |


