최근의 딥러닝 모델들은 단순히 데이터 증강(data augmentation)에 의존하지 않고, invariance(불변성) 과 equivariance(공변성) 을 모델 구조 안에 직접 인코딩(encoding) 하도록 설계되는 방향으로 발전하고 있다.
이는 학습 데이터의 양을 인위적으로 늘리지 않더라도, 모델이 효율적으로 학습하면서 다양한 입력 변화에 견고하게 대응할 수 있도록 돕는 핵심 패러다임이다.
데이터 증강은 모델이 불변성을 직접 배우도록 돕는 가장 단순하고 직관적인 방법이다.
예를 들어 고양이 이미지를 학습시킬 때, 이미지를 회전(rotate)하거나, 좌우 반전(flip), 밝기 조정(brightness), 노이즈 추가(noise) 같은 변형을 주더라도 “이건 여전히 같은 고양이다”라는 사실을 모델이 스스로 깨닫게 만든다.
이 과정을 통해 모델은 다양한 입력 상황을 경험하며, 입력의 변화에도 불구하고 출력이 변하지 않는 성질, 즉 불변성(invariance) 을 경험적으로 익히게 된다.
하지만 데이터 증강 방식에는 분명한 한계가 존재한다.
데이터의 수가 기하급수적으로 늘어나면서 학습 속도가 느려지고, 계산 자원이 많이 소모된다는 점이다.
결국 불변성을 데이터 차원에서 ‘붙여주는’ 방식이라 비용이 크며, 모델이 근본적으로 불변성을 이해한다기보다는 단순히 많은 예시를 통해 학습하는 수준에 머물게 된다.
이러한 한계를 해결하기 위해 등장한 접근이 바로 구조적 불변성(Built-in Invariance) 이다.
이는 불변성을 데이터로부터 배우는 것이 아니라, 모델의 구조 자체에 내재시키는 설계 방식이다.
즉, 모델이 태생적으로 특정 변환에 대해 변하지 않거나, 일정한 방식으로만 변하도록 만드는 것이다.
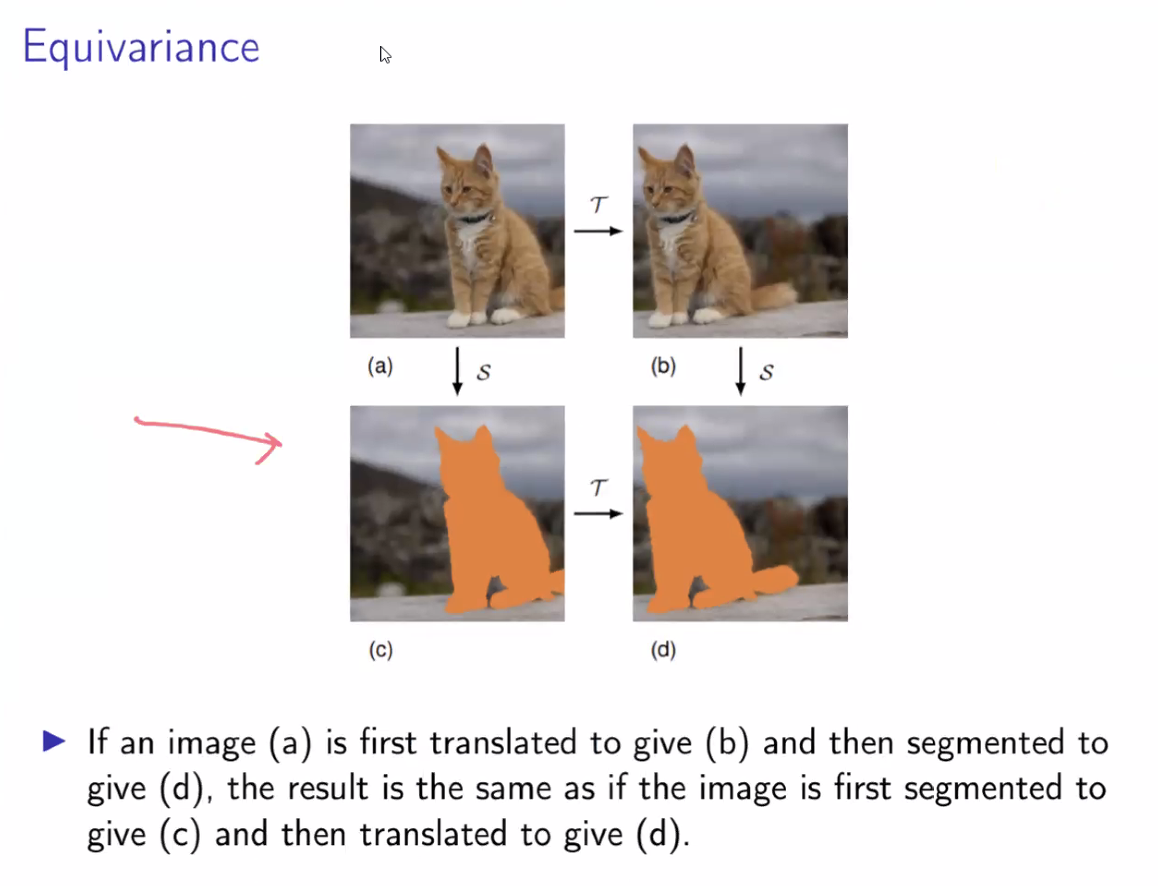
대표적인 예로 CNN(Convolutional Neural Network) 은 translation equivariance(이동 공변성) 을 갖는다.
이는 “입력이 이동하면, feature map도 동일하게 이동한다”는 성질을 의미한다.
예를 들어 이미지가 오른쪽으로 조금 옮겨지면, CNN이 추출한 특징(feature)도 같은 방향으로 옮겨진다.
이 공변성 덕분에, 모델은 “물체가 이미지 어디에 있든 동일하게 인식할 수 있는” 불변성(invariance)을 결과적으로 얻게 된다.
다시 말해, convolution 연산은 공변성(equivariance)을 통해 불변성(invariance)을 실현하는 구조적 장치를 제공하는 셈이다.
한편 Transformer는 순서 불변성(permutation invariance) 을 확보하도록 설계되어 있다.
Transformer의 self-attention 메커니즘은 입력의 순서가 달라지더라도 문맥적 의미를 유지하도록 한다.
예를 들어 “고양이가 앉아 있다”와 “앉아 있는 고양이”는 단어 순서가 다르지만, Transformer는 두 문장이 같은 의미를 지닌다는 것을 인식한다.
이처럼 self-attention 구조는 입력의 위치나 순서가 바뀌어도 전체 의미가 변하지 않도록 하는 불변성을 모델 수준에서 보장한다.
Transformer는 permutation invariance가 아니라 permutation equivariance에 가깝다.
Transformer는 입력 간의 상대적 관계를 전역적으로 파악할 수 있도록 self-attention 메커니즘을 사용한다.
self-attention은 입력의 각 위치가 문장 내 다른 모든 단어와 상호작용하도록 하여,
모델이 순서 정보에 구속되지 않으면서도 의미적 관계를 이해할 수 있게 한다.
다만 Transformer 자체는 기본적으로 순서에 불변하지 않다.
그래서 모델은 입력의 순서를 인식할 수 있도록 positional encoding(위치 임베딩) 을 추가로 사용한다.
이 덕분에 Transformer는 “위치 정보는 고려하지만, 위치에 고정되지 않는” 구조를 갖는다.
즉, 문장의 의미가 위치 변화에 완전히 무관하지는 않지만,
그 의미를 전역적으로 재해석할 수 있는 ‘순서 민감형 공변성(permutation equivariance)’ 을 가진다고 볼 수 있다.
결국 데이터 증강이 모델로 하여금 불변성을 경험적으로 학습하게 하는 방법이라면,
CNN이나 Transformer와 같은 구조적 접근은 불변성을 선천적으로 내재화한 설계 철학이라고 할 수 있다.
현대의 딥러닝은 이 두 접근 방식을 적절히 조합함으로써, 데이터 효율성과 일반화 능력을 동시에 확보하는 방향으로 진화하고 있다.
결국 데이터 증강이 모델로 하여금 불변성을
경험적으로 학습하게 하는 방법 이라면,
CNN이나 Transformer와 같은 구조적 접근은 불변성을
선천적으로 내재화한 설계 철학 이라고 할 수 있다.

'ML&AI' 카테고리의 다른 글
| 데이터의 구조를 모델이 이해한다는 것, CNN은 왜 시각 피질을 닮았을까 — CNN의 철학 (0) | 2025.10.30 |
|---|---|
| 패턴마이닝 : Support, Confidence, Lift로 보는 연관규칙: 데이터 속 숨은 관계를 해석하는 법 (0) | 2025.10.22 |
| Pattern mining (2) : Frequent Pattern Mining (0) | 2025.10.02 |
| 딥러닝 표현학습의 흐름: 프리트레이닝·파인튜닝·메타러닝·대조학습 그리고 CLIP (1) | 2025.09.11 |
| 팔로업 질문 생성(Follow-up Question Generation) 회고 + Rewarding What Matters (2024)은 TOD & 멀티턴 Flan-T5모델 다시 살펴보기 (0) | 2025.09.06 |

