대화형이든 게임 속 캐릭터든, 어떤 에이전트가 "과거의 경험을 잘 기억하고, 지금 상황에 맞게 잘 행동하려면" 메모리라는 개념이 중요하다. 딥러닝 메모리 구조를 대화형에이전트에 활용하면 더 강력한시스템이 될수 있을까?
이번학기에 딥러닝이랑 강화학습 수업을 듣다보니 찾아보게된 논문이다.
Stable Hadamard Memory: Revitalizing Memory-Augmented Agents for Reinforcement Learning
강화학습환경은 종종 POMDP이기 때문에 과거의 정보를 잘 기억하고 활용하는 메모리 시스템이 필수다. 기존의 메모리 구조들이 있었지만 장기 기억 유지가 어렵고, 불필요한 정보 제거가 잘 안되며, 반복 곱셈시 그레디언트 배니싱, 익스플로딩에 대한 문제가 있다. 그래서 SHM을 제안하는 논문이다.
대화형에이전트에서도 ReAct, Reflexion, Toolformer, AgentVerse, Voyager(Minecraft agent), MemGPT등 핫한 주제다. LLM이 자기 행동을 기록하거나 회고하거나 필요할때만 꺼내 쓰도록 하는 구조를 연구중이다. 일부는 SHM이나 ReLIC처럼 강화학습적 메모리 구조를 참조해서 LLM용 시스템에 넣고 있다.
나는 여전히 관련된 컨텍스트만 어떻게 잘 전달할수 있을까? 그로 인해 토큰도 최적화하면서(비용,속도 상관관계), 할루시네이션도 줄이고 조금더 맞춰진 대화를 사용자에게 제공할수 있을까? 에 관심이 많다.
- LLM Context Relevance score를 줄이거나 늘리는 개념
- 메모리프롬프트를 앞에 넣을지 툴로 분리할지 선택하는 메모리라우터 (이건 툴플래닝이 또 들어가기 때문에 그리고 공용으로 쓰는게 맞다는 직관적인 판단에 이렇게 설계)
- 숏텀은 슬라이딩 윈도우로, 롱텀은 벡터 시밀리러리토 접근하는 구조 (이건 이렇게 설계해봤음)
여튼 대화형 llm에이전트의 '대화 맥락 유지를 위한 메모리' 딥러닝 쪽에서 말하는 메모리는 둘이 완전 다른 개념은 아니고, 개념적으로 연결되는 지점이 꽤 있다. 논문리뷰에 들어가기 앞서 정리를 먼저 해본다.
대화형 llm에이전트의 '대화 맥락 유지를 위한 메모리' 딥러닝 쪽에서 말하는 메모리
딥러닝에서 말하는 메모리는 RNN / LSTM / GRU와 같은 시퀀스 모델의 '기억셀'이다.
- 시계열, 문장, 대화 등 순차적인 데이터를 다룰 대는 과거 정보를 기억하는 구조가 필요했다. 그래서 나온게 Recurrent Neural Network, LSTM, GRU같은 구조다. 이 모델들은 이전 입력들을 숨겨진 상태나 셀 상태에서 압축해서 기억 하도록 설계되어있다. 여기서 메모리란 각 시점의 정보를 요약해 다음 스텝에 넘겨주는 임베딩 형태의 정보 저장소다. (우리가 개발했던 숏텀메모리와 비슷한 느낌이다. 다만 학습이 가능한 형태로 내부에 유지된다는 점이 다르겠다.)
Memorry augmented neural network 여기서는 진짜 외부 메모리를 둔다.
- 이 메모리는 특정구조에 정보를 저장하고 나중에 주소 기반으로 불러온다. 키워드로 요약해서 저장하고 나중에 사용하는 이런 구조라고 생각하면 된다.
대화형에이전트에서의 메모리는?
- 보통 숏텀.롱텀으로 정의를 한다. 숏텀은 직전 몇 차례의 대화요약 ,주제, 키워드를 유지하는 것으로 RNN, LSTM의 hidden state나 attention window와 유사하다. 실제로 유사하게 설계했다.
- 롱텀메모리는 사용자의 설정, 성향, 고유정보등 변하지 않는것으로 정의한다. 딥러닝으로 보면 외부메모리와 가깝다고 생각하면 된다.
- 컨텍스트에 전달되는 측면으로 봤을때, llm에 필요한 정보만 잘 정리하여 압축해 prompt형태로 주입하게 된다.
그럼 대화형에이전트와 딥러닝에서의 메모리에 대한 개념적인 차이점은?
- 딥러닝에서의 메모리는
- 학습대상? 학습 중 업데이트 된다.
- 저장소는? 모델 내부 hidden state, memory matrix
- 사용방식은? end-to-end로 학습된다. 이말은 메모리에 어떻게 저장하고 지울지, 그걸 기반으로 어떤 행동을 할지, 이런 모든 단계가 딥러닝 모델 내부 파라미터로 학습이 된다. 메모리 조작이라는 것도 미리 룰을 짜서 넣는게 아니라, 학습 과정속에서 알아서 어떻게 이거하는게 좋은지 배우는 거라고 보면 되겠다. 즉 설계 주체는 모댈 내부 파라미터가 결정한다.
- 대화형에이전트에서의 메모리는
- 학습대상은? 주로 llm외부에서 처리 후 주입된다.
- 저장소는? 모델 외부 db형태로 관리된다.
- 사용방식은? 딥러닝에서의 사용방식과는 다르게 메모리를 벡터디비와 같은 저장소에 정리를 하고 그걸 요약해서 프롬프트에 넣어주고 어떤 정보를 넘길지 어떻게 정리할지 프로그래머가 코드로 정한다. 그러니까 이건 앤드투 앤드라고 볼수는 없다. 중간ㄴ의 메모리 조작 과정을 우리가 설계하고 조정하는 구조니까 말이다.
다시 논문리뷰로..
강화학습에이전트에게는 메모리가 반드시 필요하다. POMDP상황에서는 에이전트가 과거의 정보를 기억하지 않으면 제대로된 판단을 내릴수 없다. 하지만 여전히 좋은 메모리를 설계하는 일은 여전히 어려운 과제다. 단순히 과거 기억을 저장하는것 뿐만 아니라, 환경이 변화함에 따라 메모리를 유연하게 갱신하는 능력도 가져야 한다. 기존 메모리증강신경망 MANNs를 위해 설계된것들은 가능성을 보여주긴 했지만 이동적인 환경에서는 자주 무너졌다. 특히 보상이 드물게 주어지고 상황이 복잡한 환경에서는 에이전트가 어떤 기억은 지우고, 어떤 기억은 유지할지를 잘 판단해야 한다. 현재까지니의 메모리 모델은 이런 상황을 효율적이면서도 안정적이며 유연하게 다루지 못한다.
이 논문에서는 새로운 정보를 메모리에 기록하는 방식을 좀 더 잘 설계하는데 초점을 맞춘다. HMF(Hadamard Memory Framework)라는 통합 모델을 제안하고 있다. 이 프레임워크의 핵심은 메모리조정인데, 기존 메모리 행렬을 조정행렬과 곱한후 --> 업데이트 행렬을 더해서 --> 메모리 하나하나를 선형적으로 조정한다. 그리고 이때 하마드곱을 사용하는데 이건 메모리 행렬의 각 요소를 하나씩 곱해서 기존 메모리 셀들을 서로 섞지 않으면서 조정할수 있도록 도와준다.
POMDP의 중요한 내용은 에이전트는 실제상태 st를 직접 보지 못하고 대신 ot ~ O(st) 형태의 부분적 정보값만 얻는다. 그래서 최적의 결정을 내리면 이전의 관측값, 행동, 보상을 종합해서 판단해야 한다. 해당 논문에서는 시점 t에서의 입력정보를 아래처럼 정의한다.
xt = (ot, at-1, rt-1)
(현재 관측, 이전 행동, 이전 보상)

그리고 지금 까지의 컨텍스트들을 메모리로 만드는 함수를 아래처럼 쓴다.
Mt = f({xi}i=1~t)
즉, 시점 t까지의 모든 입력을 가지고 메모리 Mt를 만든다는 뜻이다.
즉, 이 메모리 Mt를 기반으로 가장 큰 누족 보상을 얻는 정책을 학습하는 것이다.
메모리강화신경망 내부 구조에 관한 내용을 보자.
읽기보다 중요한건 새로운 정보를 메모리에 어떻게 써넣을까? 라는 점이다. 일반적인 메모리 업데이트를 수식으로 표현하면
Mt = f(Mt-1, xt)
즉, 이전 메모리와 현재 입력으로 새로운 메모리를 만든다는 뜻이다.
Hebbian learning, Fast Weight Memory(비선형 함수를 통해 메모리를 강화하거나 감쇠시킴), DNC 좀더 정교하게 지우기, 쓰기, 가중치를 따로 계산해서 메모리를 업데이트, Linear Transformer (간단하고 빠른방식), Matrix LSTM 기존 LSTM을 확장해서 메모리도 행렬로 만듦, Fast Forgetful Memory 신경과학에서 영감받은 구조로 시간t에서 메모리를 지우고 새로운 값을 덮어쓰는방식인데 여튼 여러가지 쓰기 방식들이 있다.
이런 방식들이 있는데 전부 쓰기 방식에 따라 메모리 효율과 성능이 달라진다는게 핵심이다. 그래서 이 논문에서는 하다마드곱을 중심 연산으로 하는 일반화된 메모리쓰기 프레임워크를 제안한다.

- 조정행렬?
- 어떤 과거 정보를 약화/강화할지 정한다. 이전 메모리중 어떤 부분은 지우고, 유지할지, 강화할지 정하는 가중치 행렬을 말한다.
- 기억하고 싶은건 1보다 크게 곱하고
- 지우고 싶은건 0에 가깝게해서 악화시키고
- 그대로 두고 싶은건 1로 곱해서 유지
- 즉 Ct는 이전 메모리에 곱해져서 이셀은 남겨! 잊어! 중요! 이렇게 연산하기 위한 역할이라고 생각하면 쉽다.
- 조정행렬을 쓰면 과거 기억을 지우거나 강화할 수 있지만, 학습중에 그레디언트배니싱이나 익스플로딩 문제가 생길수 있다. 이유는 메모리의 누적 조정은 곱셈이니까 계속 곱하면 값이 0에 수렴하거나(소실), 엄청 커질수 있기 때문이다. 그래서 이부분을 해결하기 위해서 논문에서는 Stable Hadamard Memory SHM구조를 제안한다.
- 어떤 과거 정보를 약화/강화할지 정한다. 이전 메모리중 어떤 부분은 지우고, 유지할지, 강화할지 정하는 가중치 행렬을 말한다.
- 업데이트 행렬?
- 어떤 정보를 새로 메모리에 넣을지 정함

- 하다마드곱?
- 각 요소별로 곱하는 연산으로 메모리 셀들을 섞지 않게 한다. 이 방식은 메모리의 특정 부분은 지우고 다른 부분ㅇ는 남기는 식의 정밀한 조정을 가능하게 한다. 그리고 연산이 단순해서 계산속도도 빠르다.
메모리, 조정행렬, 업데이트행렬 모두 같은 차원이어야한다. 이 논문에서는 24,72,128,156 여러값을 실험했고 H가 커질수록 성능이 좋아지긴 했지만 그만큼 연산 시간도 느려지기때문에 적절한 트레이드 오프가 필요하다. (아마도 나는 숏텀메모리와 같은 부분을 구현한다고 하면 H는 64정도로 실험해보지 않을가 싶다. )
이 논문에서는 조정행렬로 SHM구조를 제안하는데, 핵심 아이디어는 조정행렬의 요소값들이 항상 너무 크기거나 작지 않도록 조정하고 이 값들이 입력에 따라 동적으로 바뀌도록 설계하는 것이다.
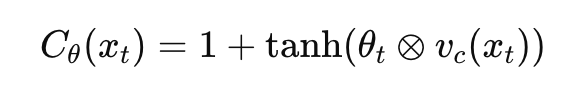
Cθ(xₜ)는
- 메모리 업데이트 할때, 이전 메모리 Mt-1에서 곱해서 어떤정보를 지우고, 남기고, 강화할지를 결정하는 조정용행렬이고, 위 수식을 해석해보면, 현재 시점에서 선택된 조정 벡터(크기 H), 입력을 메모리 차원으로 바꾼 벡터, 외적한 결과로 결과는 H*H행렬을 말한다.
vc(xₜ)은
- 입력 Xt(관측, 행동, 보상 등 포함된 벡터)를 메모리 차원에 맞게 바꿔주는 변환 함수다. 입력이 20차원인데 메모리는 64*64라면 20차원 -> 64차원으로 바꿔야된다. 즉 vc(xₜ)는 입력을 메모리 공간과 같은 차원으로 매핑하는 역할을 한다. 실제로는 W*Xt형태의 선형변환으로 구현된다.
θₜ는
- calibration parameter 조정용 파라미터다. 즉 이번 입력 Xt에 대해 어떤 식으로 기억을 조정할까? 를 정해주는 값이다. 그리고 스칼라가 아니라 벡터다.
- L개의 H차원 벡터가 들어있는 행렬이다. 논문에서는 L(다양한 조정방향의 개수)을 128을 사용했다. 각 타임스텝마다 이중 하나의 조정 방향을 샘플링해서 사용한거다.

- 논문에서는 θ라는 큰 파라미터 행렬이 있고, 거기서 θₜ = θ[lt] 식으로 한줄을 무작위로 샘플링해서 쓴다.
- 랜덤하게 샘플링하는 이유는?
- 매번 같은 조정용파라미터를 쓴다면 모든 timestep의 조정방식이 비슷해진다. 그럼 누적해서 곱할때마다 특정 방향으로 치우치거나 기울기가 터져버린다. 그래서 매 스텝마다 독립적인 방향으로 조정하도록 일부 랜덤성을 줘서 전체적으로 더 안정적인 곱이 되게 유도하는거다.
- SHM의 구성요소중에 어떤게 진짜 중요한지 실험한 것도 논문에 있는데, θₜ 어떻게 만들고 쓰느냐에 따라 성능이 크게 달라졌다. 랜덤하게 쓸때 즉 매 timestep마다 하나씩 랜덤하게 뽑을때 성능, 안전성 모두 좋았다고 한다. 그리고 랜덤샘플링했기 때문에 100step 이상도 기울기가 잘 유지되었다고 한다. 이는 tanh + 랜덤 + 외적 의 조합덕분임
tanh()함수는 왜 쓰는가
- 입력이 클수록 +1에 수렴, 작을수록 -1에 수렴한다. 즉 값을 부드럽게 제한해준다.
- θₜ ⊗ vc(xₜ)의 결과는 H×H 행렬인데, tanh함수와 +1한 효과로 Cθ(xt)[m,k]∈[0,2] 즉 직관적인 숫자 범위로 해석 가능하게 만든거다.
- 0이면 메모리 셀 지움 / 1이면 그대로 유지 / 2이면 해당 셀을 강화
이렇게 만들어진 Cθ(xₜ) 조정용파라미터는 이전 메모리 Mt-1에 요소별로 곱해서 지울지, 유지할지, 강화할지 즉 조정을 하게 된다.
Visual Match, Key-to-Door 을 통해서 메모리 행렬(Mt)과 조정행렬(Ct)을 시각화 했는데, 기억 -> 잊기 -> 회상 의 흐름으로 잘 구현되었다고 한다. 에이전트가 기억해야 할 것과 버려야할 것을 구분해서 학습하고있다는걸 증명한건데 SHM이 기억을 조정하는 과정이 실제로 시간에 따라 어떻게 변하는지를 시각적으로 보여주는 실험결과이다.
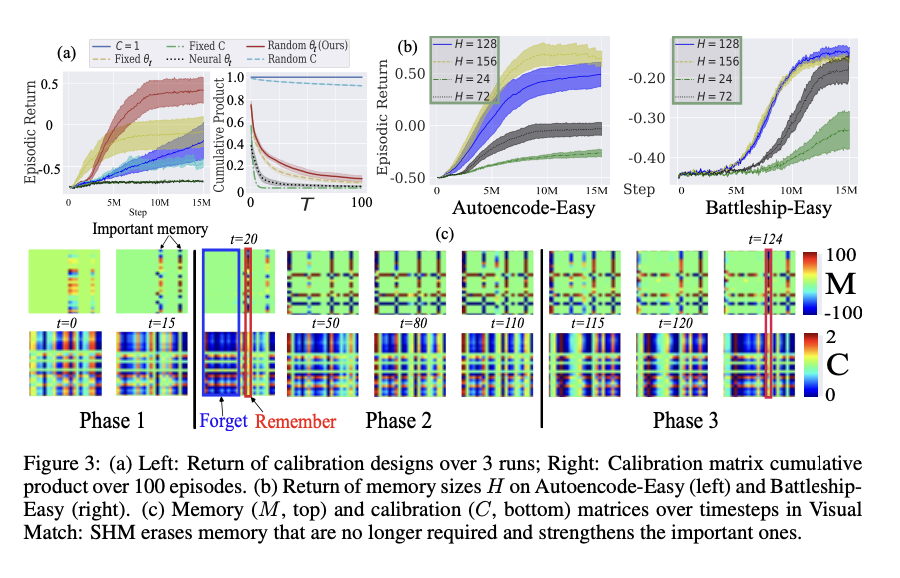
Visual Match환경에서 에이전트가 행동한 3단계에 걸쳐 메모리 행렬과 조정행렬이 시간의 흐름에 따라 t=0 ~ 124 어떻게 변하는지를 보여주는 시각화다.
Visual Match환경는
- phase1 : 에이전트는 색상코드를 관측한다. (보상없음) 이 정보를 기억해둬야 나중에 쓸수있다.
- phase2 : 에이전트는 사과를 줍는다. 보상은 있는데 최종 목표와는 관계없는 행동이다.
- phase3 : 에이전트는 색상 코드에 맞는 문을 찾아야 한다. 즉 phase1에서 본 색상코드를 기억해야 한다.
위쪽에 메모리행렬 Mt를 보면
- 각 칸은 메모리행렬의 [m,k] 요소이고 값이 클수록 빨간색 = 즉 기억이 강하게 저장된걸 의미한다.
- 값이 작을수록 파란색인데 이는 기억이 거의 없음을 의미한다.
- 100 ~ -100은 논문에서 M ∈ ℝ^{H×H} 을 의미한다.
아래쪽에 조정행렬 Ct를 보면
- 메모리 M에 곱해지는 조정필터인데
- 색상의 범위가 0 ~ 2 이다.
- 0: 파랑 : 완전히 잊어라
- 1: 흰색 : 그대로 유지
- 2: 빨강 : 강하게 강화
시간의 축으로 그래프를 읽어보면
- t=0은 초기 상태라 메모리가 거의 비어있고,
- t=15이 되면 페이지1은 끝났고, 색상코드가M에 기록됐다. 이 부분이 important memory로 표시된 부분이다.
- t=20은 페이지2 시작이고, C에서 파란부분 -> 지워 Forget 진다는 의미다. C에서 빨간 부분은 중요한 정보는 유지 Remember
- t = 50 / 80 / 110은 불필요한 정보는 계속 들어오지만 중요 정보는 남아잇다. 유지단계
- t = 115 ~ 124은 처음에 기억했던 정보가 다시 쓰이기 직전.M에 남은 빨간 영역이 그대로 살아있음 → 기억 유지 성공!
SHM은 중요한 정보는 기억 속에 보존하고, 불필요한 정보는 자동으로 지워버릴 수 있다는 것을 시간 흐름과 함께 시각적으로 증명한 실험이다.
강화학습 환경에서 딥러닝기반 메모리층이 있고 그리고 이런 상황 (강화학습 에이전트가 과거 기억을 바탕으로 행동헤야 할때, 에이전트가 부분 정보만 관측한 환경일때, 기존 메모리 모델에서 그레디언트 배니싱/익스플로딩 문제가 있을때)일때 다시 한번 보면 좋은 논문인거 같다.
논문리뷰하고 드는 내 생각을 끄젹여 보자.
에이전트시스템을 개발하면 당연히 어떻게 어느시점에 효율적인 컨텍스트를 잘 주입할수잇을까? 하면 메모리시스템을 떠올릴수 밖에 없다.
긴대화를 언제까지다 넣을수는 없으니까. LLM에 문맥을 넣는 건 결국 컨텍스트 윈도우 안에서만 가능하다. 암만 커져도 그걸다 쓸수는.. ㅎㅎ 최적화를 해야 할루시네이션도 줄고,비용, 속도도 얻을수있다.
그럼 이때 SHM같은 개념이 왜 유용할까?
모든 대화를 넣는 대신, 어떤 기억은 지우고, 어떤 건 요약해서 남겨두고, 어떤 건 강화해서 컨텍스트에 남겨두자.
작년에 나는 주제를 기반으로 요약을 하면서 아래와 같은 데이터를 추출했다.
[대화기록들] → LLM 평가
→ 중요도 스코어 / 주제 태그
→ priority에 따라 저장 or 제거
↓
메모리 M
└─ Long-term: 벡터 DB / JSON key-value
└─ Short-term: SLIDING context (1시간안에 주제가 같은 토픽에 요약된 데이터 N개 유지)연관성이 높은 주제로 접근했는데, 관심사가 비슷한 공간이 아니면 즉 일상의 대화라는 공간이라는 이런 주제기반의 트리거링하는건 적합하지 않다는 생각이다. 차라리 일정/이벤트 기반 인터렉션을 조금더 집중하는 메모리 설계를 했다면? 이라는 생각이 든다.
반대로 관심사 기반 대화에서는 주제기반으로 트리거링하는 알고리즘은 적합했겠다라는 생각도 있다. (암만 다시 생각해봐도 일상의 대화를 나눈다는건 유사한 관심사랑은 동떨어진건데 ㅎㅎ 관심사도 하고 싶고 일상대화도 하고 싶고 ㅎㅎ 다하고 싶은건 뭐하나 제대로 못한다는것.. ㅎ 여튼)
기억을 조절하는 법. 참 어렵고 그래서 찾아보게 되는 부분인거 같다.
https://arxiv.org/abs/2410.10132 이 논문을 추천한다.
Stable Hadamard Memory: Revitalizing Memory-Augmented Agents for Reinforcement Learning
Effective decision-making in partially observable environments demands robust memory management. Despite their success in supervised learning, current deep-learning memory models struggle in reinforcement learning environments that are partially observable
arxiv.org
'ML&AI' 카테고리의 다른 글
| 카페 챗봇으로 배우는 강화학습: 벨만 방정식부터 TD 학습까지 알아보자. (3) | 2025.04.14 |
|---|---|
| 피드포워드 신경망(Feedforward Neural Networks) (0) | 2025.03.24 |
| DeepSeek 정리해보자 (1) | 2025.02.05 |
| Building effective agents (3) | 2025.01.03 |
| Are Large Language Models All You Need for Task-Oriented Dialogue? (0) | 2024.12.08 |



