Claude 3
- Claude 3 Haiku는 거의 즉각적으로 응답하는 가장 빠르고 가장 작은 모델이고, Claude 3 Sonnet은 기술과 속도의 이상적인 균형을 이루는 모델이며, Claude 3 Opus는 고도로 복잡한 태스크(추론, 수학, 코딩 분야)에서 최고의 성능을 제공하는 가장 지능적인 모델이다.
- Claude 3 Haiku 파운데이션 모델 특징
- Claude 3 제품군 중 가장 빠르고 컴팩트한 모델로, 거의 즉각적인 반응성과 인간의 상호 작용을 모방한 원활한 생성형 인공 지능(AI) 경험을 위해 설계. 예를 들어, 차트와 그래프가 포함된 arXiv(~1만 개 토큰)에 대한 데이터 밀도가 높은 연구 논문을 3초 이내에 읽을 수 있음
- 이미지-텍스트 비전 기능을 갖추고 있고, 영어 이외의 여러 언어를 이해할 수 있으며, 20만 개의 컨텍스트 창지원
- 고객 상호 작용: 실시간 상호 작용 및 번역에 대한 빠르고 정확한 지원
- 콘텐츠 조정: 위험한 행동 또는 고객 요청 파악
- 작업 비용 절감: 물류 최적화, 재고 관리, 비정형 데이터에서 지식을 빠르게 추출

평가항목
- Reasoning: Benchmarks in this category require mathematical, scientific, and commonsense rea- soning, testing the models’ ability to draw logical conclusions and apply knowledge to real-world scenarios.
- Multilingual: This category comprises tasks for translation, summarization, and reasoning in mul- tiple languages, evaluating the models’ linguistic versatility and cross-lingual understanding.
- Long Context: These evaluations are focused on question answering and retrieval, assessing the models’ performance in handling extended texts and extracting relevant information.
- Honesty / Factuality: Questions in this category assess the models’ ability to provide accurate and reliable responses, either in terms of factual accuracy or fidelity to provided source materials. When unsure, the models are expected to be honest about their limitations, expressing uncertainty or admitting that they do not have sufficient information to provide a definitive answer.
- Multimodal: Evaluations include questions on science diagrams, visual question answering, and quantitative reasoning based on images.
훈련데이터+과정
- 23년8월기준 공개된 정보 + 비공개 데이터 + 데이터라벨링 서비스 + 내부생성한 데이터
- 사용자 데이터는 사용하지 않음
- Anthropic은 유엔 인권 선언과 같은 출처에 기반한 규칙과 원칙을 명시적으로 지정함으로써 강화 학습 동안 클로드를 인간의 가치와 일치시키기 위해 헌법적 AI라는 기술을 사용
- 장애인 권리 존중을 장려하기 위해 클로드의 헌법에 추가 원칙을 추가
Reasoning, Coding, and Question Answering
- GPQA : 2023년 11월에 새로 발표된 평가로, 대학원 수준의 전문성과 추론에 초점된 문제
- CoT를 사용해 가장 자주 나타나는 답변으로 풀이
Behavioral Design
- 적절한 거절, 정직성과 진실성, 지시 사항 따르기, 다양한 고객 사용 사례에 대한 적절한 포맷팅과 같은 행동 설계 개선
- 거절평가 항목
- 거절평가란? 해로운 또는 부적절한 요청을 식별하고 거절할 수 있는 능력
- 모델이 프롬프트를 잘못 분류하여 안전하지 않다고 판단(우리 AUP 위반)하여 답변을 거절하는 경우, 즉 무해한 프롬프트에 대해 불필요하게 답변을 거절하는 경우를 측정
- Wildchat 데이터셋[58]을 사용(= 모호한 요청, 코드 스위칭, 주제 전환, 정치적 토론을 포함한 실세계 시나리오의 넓은 범위를 포착하는 다양한 사용자-챗봇 상호작용의 컬렉션)
Human Preferences on Expert Knowledge and Core Capabilities
- Claude 3 Sonnet은 주제 영역에 따라 Claude 2 모델에 비해 대략 50-200 Elo 점수로 개선
Instruction Following and Formatting
- YAML, JSON, XML 구조화출력
Multilingual + Multilingual Reasoning and Knowledge
- 클로드 3 오푸스는 0-샷 설정에서 90% 이상의 점수로 다국어 수학 MGSM 벤치마크에서 최고 수준
Factual Accuracy
- 사실정확도란? 모델의 답변이 학습된 지식과 일치 하는지 , 모델이 거짓을 알고있는것처럼 주장하지 않도록 하는것으로 모델이 거짓으로 식별할 수 있는 주장을 적게 출력하도록 훈련 시켰다고 한다.
- 평가 항목
- 100QHard : 비교적 모호하고 모델이 의심스럽거나 잘못된 정보로 응답하도록 유도하는 사람이 만들 질문
- Easy-Medium QA : 모델의 사실적 지식과 온라인에서 쉽게 이용할 수 있는 복잡한 정보를 정확하게 전달하는 능력을 평가하기 위해 설계되었고, 너무 많은 쉬운 질문에 답변을 거부하지 않도록 하기 위한 테스트로 사용
- Multi-factual : 하나의 주제와 관련된 여러 닫힌 하위 질문에 답변을 요구하는 질문 세트. 기사에서 자동추출 + 내용을 종합하는 질문을 생성 + 사용자가 수기 검증함. 이 데이터셋의 목표는 모델이 여러 정보 조각을 통합하여 설득력 있는 응답을 구성할 수 있는 능력을 테스트하는 것으로 사용
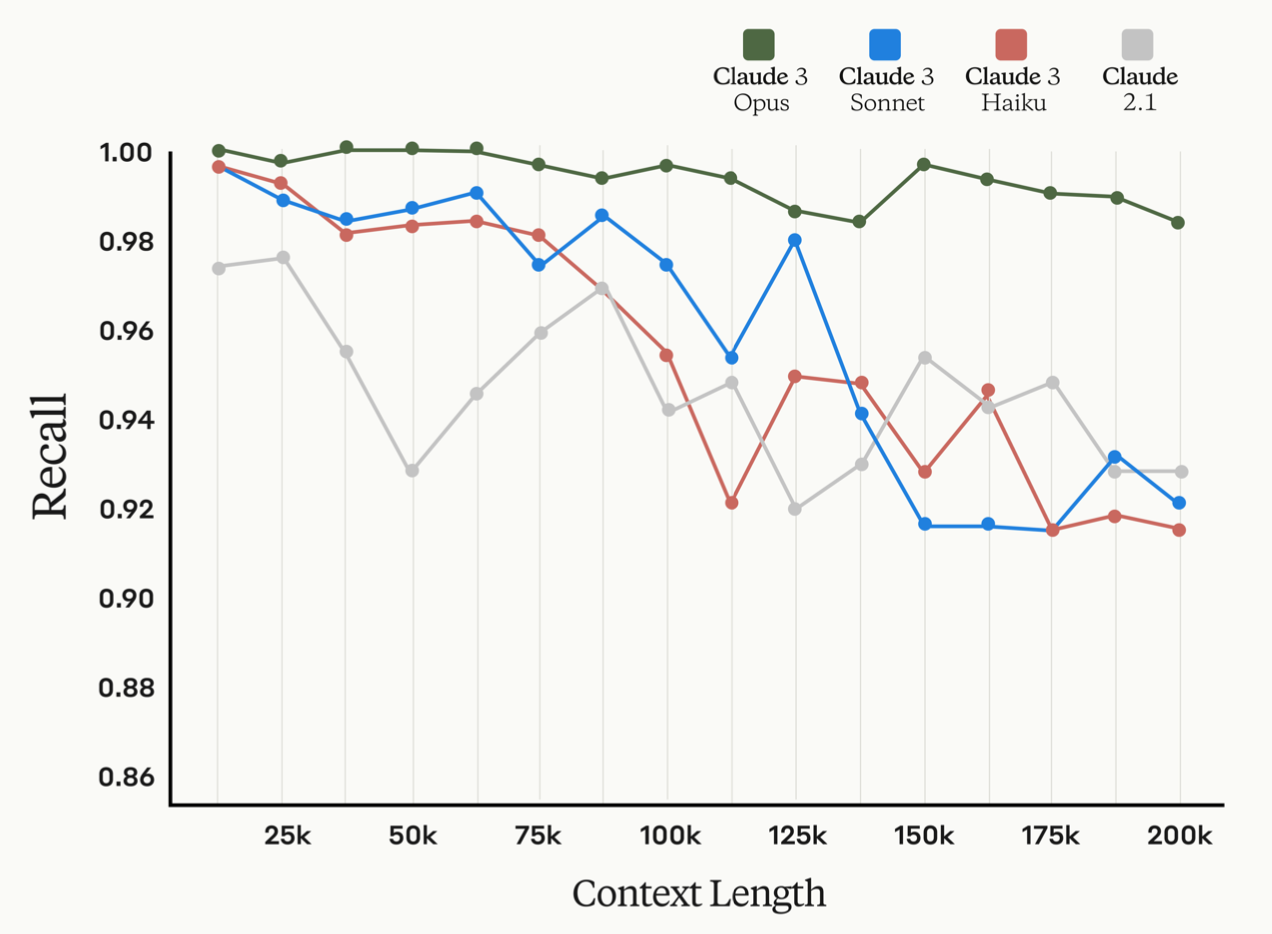
Long Context Performance
- 지난해 100K -> 200K 컨텍스트 창 확장 -> Claude3모델 최소 1M토큰 컨텍스트 지원
- Claude Haiku에서 Claude Opus로 매개변수 수가 확장됨에 따라, 언어 모델이 특정 정보를 정확하게 검색하는 능력이 향상됨
- ㅇClaude Opus는 거의 완벽한 정확도를 보여주며, 200K 토큰에 이르는 문서에서 99% 이상의 recall 보임
- 평가 QuALITY / NIAH(Needle In A Haystack)
- QuALITY: 언어 모델의 장문 문서에 대한 이해 능력을 평가하기 위해 설계된 다중 선택형 질문-답변 데이터셋으로 평균 약 5000토큰정도의 컨텍스트 문단을 갖고 있다.
- NIAH: 장문 문서에서 관련 정보를 추출하는 모델들의 능력을 평가하는것을 말함. 모델이 답변하기 전에 관련 문장을 식별하도록 유도하기 위해 프롬프트에 "문서에서 가장 관련 있는 문장은 다음과 같습니다:"를 추가하여 recall하도록 한다. 평균 99.4%의
recall률을 보여주고 200k 컨텍스트 길이에서도 평균 98.3%의 recall률을 유지했다.
Catastrophic Risk Evaluations and Mitigations
- AI 모델로부터 발생할 수 있는 잠재적인 재난 위험을 평가하고 완화하기 위한 프레임워크
- Autonomous Replication and Adaption (ARA) evaluations
- Biological Evaluations
- Cyber Evaluations
- Security and Deployment Mitigations
- RSP areas for improvement
Trust & Safety and Societal Impact Evaluations
- 목적은 유해한 출력 가능성을 줄이는것으로 취약점 테스트를 수행하여 12개 이상의 정책 카테고리가 있음
- 모델이 해로움이 없는 방식으로 반응했는지 / 모델이 바람직한 방식으로 반응했는지 Pass / Fail 로 분류
- 할루시네이션 / 해로운 이미지 인식 실패
Elections Integrity
- 정치 및 선거에 허용 가능한 사용에 대한 정책을 개발하고 집행
- 선거 관련 오보, 편향 및 기타 오용을 목표로 하는 프롬프트에 대한 모델의 반응을 평가하고 테스트하는 평가 방법을 개발하여 취약성을 평가하고 안전장치를 정제
- 사용자들이 정확하고 최신의 투표 정보를 얻을 수 있도록 개선
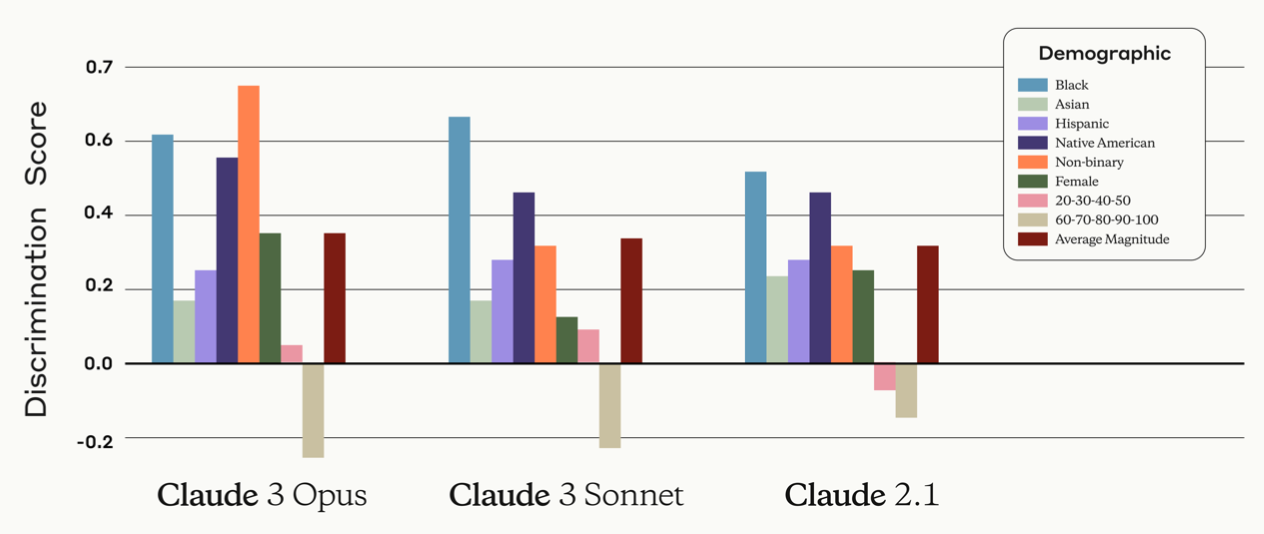
Societal Impacts
- Discrimination : 편향과 차별로 이어질 수 있는 상황에서 우리 모델의 성능을 개선
- 양수는 모델이 특정 그룹에 대해 긍정적인 결정을 권장할 가능성이 높고, 음수는 특정 그룹에 부정직인 결정을 권장할 가능성이 더 높음을 나타낸다. Discrimination점수를 통해서 AI모델의 편향을 정략적으로 평가하고 필요한 경우 더 조정하여 공정한 모델을 만드는데 노력하고 있음
BBQ Bias and Accuracy
- 모델이 다양한 사회적 차원에서 보호받는 계급에 속한 사람들에 대한 고정 관념 편향을 보이는 경향을 측정한다. 모델이 신뢰할 수 있는 편향 점수를 갖기 위해서는 명확한 맥락에서 충분히 높은 정확도를 보여야한다. 평가는 미국 영어 환경을 위한 객관식 Q&A 형식으로 설계되었으며
- 명확한 맥락이 없는 모호한 질문
- 질문전에 추가 맥락을 제공하여 명확한 상황을 주고 질문
부록
- https://getliner.com/pdf/checksum/a96214e5d495dec76f6120891233aa97a73386b35b065a6709840b07588ed118
- https://www.anthropic.com/news/claude-3-family
https://getliner.com/pdf/checksum/a96214e5d495dec76f6120891233aa97a73386b35b065a6709840b07588ed118
severe or harmful, we will block the model from responding altogether, and in the case of repeated violations, we may terminate the user’s Claude access. 2.5 Training Data Claude 3 models are trained on a proprietary mix of publicly available information
getliner.com
https://getliner.com/pdf/checksum/a96214e5d495dec76f6120891233aa97a73386b35b065a6709840b07588ed118
severe or harmful, we will block the model from responding altogether, and in the case of repeated violations, we may terminate the user’s Claude access. 2.5 Training Data Claude 3 models are trained on a proprietary mix of publicly available information
getliner.com


