https://huggingface.co/google-t5/t5-large
검색 평가자를 활용하여 검색된 문서의 품질을 평가하는 방법론이다. CRAG는 검색 결과를 개선하기 위해, 핵심정보에 초점을 맞추기 위한 알고리즘을 사용한다.
방법론
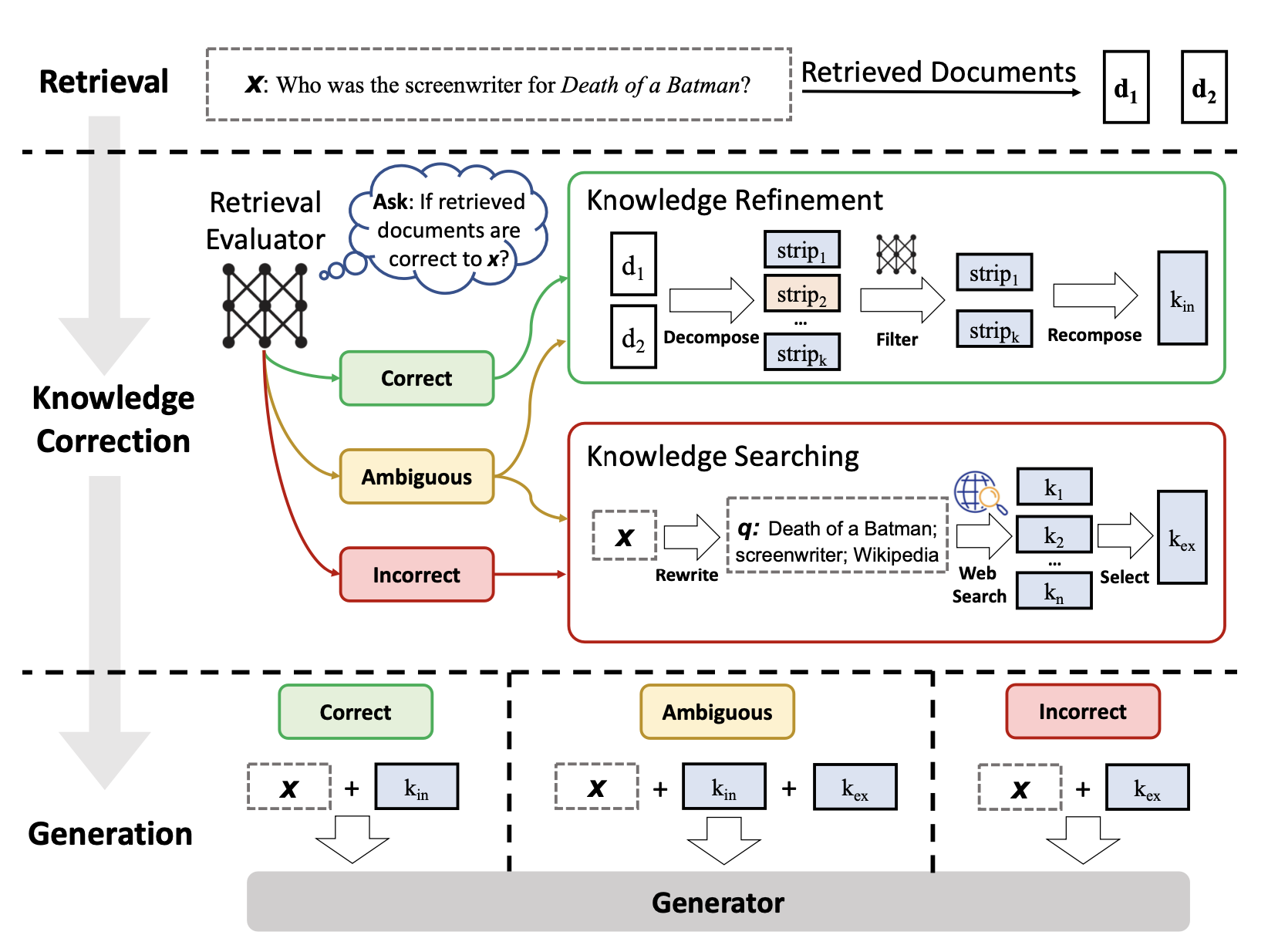
- 입력쿼리와 검색된 문서가 주어지면, 검색된 문서의 관련성 점수를 추정한다.
- 척도
- 정확, 부정확, 애매
- 정확
- 더 정밀한 데이터로 정제한다.(long context reorder처럼 해도될듯)
- 부정확
- 검색된 문서는 버리고, 2차 검색을 한다.
- T5-large모델
응용한다면
- 현재 후보군에서 답변을 할수 없다면 정보없음으로 응답하도록 되어있는데, 이런 경우 부정확/애매 라고 판단하고 2차 검색을 시도하는건 활용할만 하다.